





Avant propos...▲
Je tiens à remercier l'ÃĐquipe de developpez.com pour leurs prÃĐcieux conseils, suggestions ou corrections, et tout particuliÃĻrement keulkeulNemek et ClaudeLELOUP.
Je les en remercie.
JSR 334 - Petites amÃĐliorations du langage (le projet "Coin")▲
L'objectif du projet "Coin" est d'apporter de petites modifications au langage. On est loin ici des "rÃĐvolutions" de Java 5.0 (Generics, enums, annotations...). L'idÃĐe principale ÃĐtant d'apporter de petits correctifs ou ÃĐvolutions simples et efficaces pour faciliter la vie du dÃĐveloppeur.
Expression littÃĐrale binaire▲
En Java, comme dans un grand nombre de langages, les expressions numÃĐriques entiÃĻres peuvent Être reprÃĐsentÃĐes de trois maniÃĻres distinctes :
- le plus couramment, en notation dÃĐcimale (exemple : 255)Â ;
- en notation hexadÃĐcimale, prÃĐfixÃĐe par 0x (exemple : 0xff)Â ;
- en notation octale, prÃĐfixÃĐe par 0 (exemple : 0377).
DÃĐsormais, le langage s'enrichit avec la notation binaire, prÃĐfixÃĐe par 0b, qui permet donc de reprÃĐsenter un nombre directement sous sa forme binaire (exemple : 0b11111111).
// Un 'byte' (sur 8 bits)
byte aByte = (byte)0b00100001;
// Un 'short' (sur 16 bits)
short aShort = (short)0b1010000101000101;
// Quelques 'int' (sur 32 bits) :
int anInt1 = 0b10100001010001011010000101000101;
int anInt2 = 0b101; // Les zÃĐros inutiles peuvent Être ignorÃĐs
int anInt3 = 0B101; // Le B peut Être en minuscule/majuscule
// Un 'long' (sur 64-bit)
long aLong = 0b1010000101000101101000010100010110100001010001011010000101000101L;Le principal intÃĐrÊt ÃĐtant de simplifier la manipulation de valeurs binaires, en permettant de les reprÃĐsenter directement sous cette forme, ce qui facilite la lecture du code pour la manipulation des bits.
Formatage des expressions numÃĐriques▲
Comme dans la majoritÃĐ des langages, les expressions numÃĐriques sont reprÃĐsentÃĐes par une suite de chiffres sans aucun sÃĐparateur que ce soit, si ce n'est le point qui sÃĐpare la partie entiÃĻre de la partie dÃĐcimale pour les valeurs flottantes.
Toutefois, lorsqu'on manipule des expressions numÃĐriques reprÃĐsentant des nombres assez grands, on peut vite se retrouver avec des problÃĻmes de lisibilitÃĐ. Il faut alors "compter" le nombre de chiffres prÃĐsents dans l'expression. Java 7 apporte une solution à ce problÃĻme, en permettant d'utiliser le caractÃĻre underscore ( _ ) au milieu de n'importe quelle expression numÃĐrique afin de sÃĐparer des groupes de chiffres de maniÃĻre totalement arbitraire, afin de rendre le tout plus lisible :
double oneMilliard = 1__000_000_000.000_000;
long creditCardNumber = 1111_2222_3333_4444L;
long hexBytes = 0xFF_EC_DE_5E;
long hexWords = 0xCAFE___BABE;
long bytes = 0b11010010_01101001_10010100_10010010;Le seul et unique intÃĐrÊt consiste à amÃĐliorer la relecture du code. La prÃĐsence des underscores dans une expression numÃĐrique n'a bien sÃŧr strictement aucun impact sur le code gÃĐnÃĐrÃĐ ni sur la valeur de l'expression.
Les underscores doivent impÃĐrativement Être situÃĐs entre deux caractÃĻres numÃĐriques. Ils ne peuvent donc pas Être utilisÃĐs en dÃĐbut ou fin de l'expression, ni autour du sÃĐparateur de dÃĐcimales pour les nombres rÃĐels.
Exemples de valeurs incorrectes : 3_.14, _1000, 10_, 0x_1...
Switch sur les String▲
Fini les multiples if/else pour comparer la valeur d'une chaine ! Il est enfin possible d'utiliser un switch sur une String, afin de comparer une chaÃŪne de caractÃĻres avec des valeurs constantes (dÃĐfinies dÃĻs la compilation) :
String action = ...
switch(action) {
case "save":
save();
break;
case "save-as":
saveAs();
break;
case "update":
update();
break;
case "delete":
delete();
break;
case "delete-all":
deleteAll();
break;
default:
unknownAction(action);
}Tout comme le switch(enum), le switch(String) n'accepte pas de valeur null (cela provoquera une exception).
En plus d'une meilleure lisibilitÃĐ, cela permet ÃĐgalement au compilateur de gÃĐnÃĐrer un code bien plus efficace qu'une succession de if/else. Le switch(String) se dÃĐcompose en rÃĐalitÃĐ en deux switches. Le premier se base sur le hashCode() afin de sÃĐparer les diffÃĐrentes valeurs plus facilement, avant de vÃĐrifier l'ÃĐgalitÃĐ via equals(). Ceci permettra de dÃĐterminer l'index du second switch, qui reprend le mÊme format que le switch(String) original, mais en utilisant des valeurs numÃĐriques (ce qui permet de conserver le mÊme ordre des case dans tous les cas).
Ainsi le code ci-dessus est à peu prÃĻs ÃĐquivalent au code suivant :
String action = ...
int switchIndex = -1;
// On dÃĐcoupe
switch (action.hashCode()) {
case 3522941: // "save".hashCode()
if ("save".equals(action))
switchIndex = 1;
break;
case 1872766594: // "save-as".hashCode()
if ("save-as".equals(action))
switchIndex = 2;
break;
case -838846263: // "update".hashCode()
if ("update".equals(action))
switchIndex = 3;
break;
case -1335458389: // "delete".hashCode()
if ("delete".equals(action))
switchIndex = 4;
break;
case 1763419775: // "delete-all".hashCode()
if ("delete-all".equals(action))
switchIndex = 5;
break;
}
switch (switchIndex) {
case 1: // "save"
save();
break;
case 2: // "save-as"
saveAs();
break;
case 3: // "update"
update();
break;
case 4: // "delete"
delete();
break;
case 5: // "delete-all"
deleteAll();
break;
default:
unknownAction(action);
}Lorsque les diffÃĐrentes chaÃŪnes du switch disposent de hashCode() diffÃĐrents, l'accÃĻs se fera donc en temps constant quelle que soit la valeur recherchÃĐe, contrairement aux multiples if/else oÃđ le temps dÃĐpend de l'emplacement dans la liste.
Dans le cas de deux chaÃŪnes du switch(String) (ce qui est peu probable dans un cas rÃĐel), le premier switch utilisera une succession de if/else pour les distinguer. Par exemple les chaÃŪnes "bb" et "cC" possÃĻdent le mÊme hashCode(). Lorsqu'on les utilise dans un switch(String), cela gÃĐnÃĐrera dans le premier switch un seul case gÃĐrant les deux valeurs :
case 3136: // "bb".hashCode() OU "cC".hashCode();
if ("bb".equals(action))
switchIndex = 3; // selon l'index du case dans le switch original
else if ("cC".equals(action))
switchIndex = 7; // selon l'index du case dans le switch original
break;Type Inference sur la crÃĐation d'instance Generics (le losange)▲
Le "Type Inference" est une notion apparue avec les Generics de Java 5.0. Elle permet au compilateur de dÃĐterminer le type du paramÃĐtrage Generics selon le contexte, afin d'ÃĐviter d'avoir à le prÃĐciser explicitement dans le code.
Dans Java 7 le "Type Inference" a ÃĐtÃĐ amÃĐliorÃĐ afin de prendre en compte le cas particulier de la crÃĐation d'une instance Generics. En effet, la plupart du temps une crÃĐation d'instance est affectÃĐe à une rÃĐfÃĐrence dont le type est dÃĐclarÃĐ avec le mÊme paramÃĐtrage Generics. Cela aboutit à une rÃĐpÃĐtition qui peut s'avÃĐrer assez lourde dans certains cas :
List<String> list = new ArrayList<String>();
Map<Reference<Object>,Map<String,List<Object>>> map = new HashMap<Reference<Object>,Map<String,List<Object>>>();Avec l'amÃĐlioration du "Type Inference" de Java 7, le compilateur pourra donc retrouver implicitement le paramÃĐtrage Generics de la crÃĐation de l'instance, selon celui utilisÃĐ dans la variable à laquelle on l'affectera.
List<String> list = new ArrayList<>();
Map<Reference<Object>,Map<String,List<Object>>> map = new HashMap<>();Le paramÃĐtrage Generics du constructeur est simplement omis, si bien qu'il ne reste plus que les crochets <>, d'oÃđ le surnom de "syntaxe en losange".
Cela permet d'ÃĐviter de saisir deux fois la liste des paramÃĻtres Generics (une fois à la dÃĐclaration et une fois lors de la construction de l'instance).
Warning amÃĐliorÃĐ sur les ellipses paramÃĐtrÃĐes via les Generics▲
Attention : ceci est une fonctionnalitÃĐ trÃĻs spÃĐcifique et assez obscure qui sera sÃŧrement mÃĐconnue par la plupart des dÃĐveloppeurs.
Avant toute chose, il faut bien comprendre certaines spÃĐcificitÃĐs du langage.
- Les tableaux Java ne sont pas type-safe. C'est-Ã -dire que le compilateur ne peut pas vÃĐrifier la cohÃĐrence du type des donnÃĐes. Tout ceci est effectuÃĐ Ã l'exÃĐcution et peut donc provoquer des erreurs (ArrayStoreException).
- à l'inverse, le compilateur assure la cohÃĐrence du typage des Generics via des vÃĐrifications dÃĻs la compilation du code, ce qui garantit un code type-safe qui s'exÃĐcutera sans aucune erreur de typage à l'exÃĐcution (à condition que le code compile sans warning).
Du fait de leur approche à l'opposÃĐ l'une de l'autre, l'utilisation de tableaux couplÃĐs aux Generics est trÃĻs risquÃĐe. En effet du fait que le paramÃĐtrage Generics est perdu à l'exÃĐcution, la vÃĐrification du type des tableaux ne peut pas Être effectuÃĐe complÃĻtement à l'exÃĐcution, et dans certains cas il est impossible de vÃĐrifier cela à la compilation.
La faille vient du fait que tous les tableaux peuvent Être castÃĐs vers le type "parent" jusqu'à Object[], et dans ce cas-là , il est impossible de vÃĐrifier la cohÃĐrence du code à la compilation. En effet cela permet de mettre un peu n'importe quoi dans le tableau, avec un typage vÃĐrifiÃĐ Ã l'exÃĐcution. Or avec les Generics, on perd une partie de cette information à l'exÃĐcution, puisqu'on ne connait alors que le 'raw-type', c'est-à -dire le type de base sans son paramÃĐtrage Generics. Il est donc impossible d'effectuer une vÃĐrification complÃĻte à l'exÃĐcution. Pour ÃĐviter ce genre de problÃĻme, la crÃĐation de tableau Generics est interdite. En effet si ceci ÃĐtait autorisÃĐ, on pourrait facilement "casser" (volontairement ou non) le cÃītÃĐ typesafe des Generics :
List<String> listString = ...
List<Integer> listInteger = ...
List<String>[] strings = new List<String>[2]; // ceci est interdit par le langage
Object[] objects = strings;
objects[0] = listString; // OK
objects[1] = listInteger; // OK car le 'raw-type' est List !!!
// objects[1] contient un List<Integer> ce qui est "lÃĐgal".
// Or objects[1] correspond à strings[1], et là c'est incorrect !Le compilateur ne peut pas dÃĐtecter ce genre de problÃĻme, et il ne peut pas gÃĐnÃĐrer de warning sur ce type de code, car en dehors de la crÃĐation du tableau Generics (qui provoque une erreur) toutes les autres opÃĐrations sont parfaitement "lÃĐgales" !
Note : on peut rencontrer le mÊme genre de problÃĻme lorsqu'on manipule des tableaux non paramÃĐtrÃĐs (List[] au lieu de List<String>[]) ou des types sans paramÃĐtrage (List au lieu de List<String>). Ces syntaxes sont requises pour des raisons de compatibilitÃĐ avec d'anciennes API, mais à l'inverse des tableaux paramÃĐtrÃĐs, le compilateur pourra signaler tout problÃĻme potentiel via un warning...
Il y a toutefois une faille dans le systÃĻme : l'ellipse de Java 5.0. En effet cette derniÃĻre est implÃĐmentÃĐe via l'utilisation d'un tableau, et comme elle peut Être utilisÃĐe avec des Generics il devient possible de crÃĐer des tableaux paramÃĐtrÃĐs :
public void exemple(List<String>...strings) {
// 'strings' est un tableau de List<String>
}DÃĻs lors qu'on utilise une mÃĐthode à ellipse avec un type paramÃĐtrÃĐ, on obtient un warning assez curieux pour nous prÃĐvenir du problÃĻme. Exemple :
List<Reference<String>> list = new ArrayList<Reference<String>>();
Collections.addAll(list, ref1, ref2, ref3); // warning
// warning: [unchecked] unchecked generic array creation of type Reference<String>[] for varargs parameter
// Collections.addAll(list, ref1, ref2, ref3);Ce warning nous signale la crÃĐation implicite d'un tableau de type paramÃĐtrÃĐ, dont la cohÃĐrence du typage ne peut pas Être garantie par le compilateur.
Le problÃĻme vient du fait que jusqu'alors, ce warning ÃĐtait uniquement gÃĐnÃĐrÃĐ lors de l'appel de la mÃĐthode, mais jamais sur son implÃĐmentation. Ainsi le code suivant compilait sans erreur ni warning :
public static <T> boolean addAll(Collection<? super T> c, T... elements) {
boolean result = false;
for (T element : elements)
result |= c.add(element);
return result;
}Or cela dÃĐpend uniquement de la maniÃĻre dont ce tableau sera utilisÃĐ Ã l'intÃĐrieur de la mÃĐthode à ellipse. Avec Java 7 le code ci-dessous gÃĐnÃĻre donc un nouveau warning de compilation pour signaler le problÃĻme au plus tÃīt :
warning: [unchecked] Possible heap pollution from parameterized vararg type T
public static <T> boolean addAll(Collection<? super T> c, T... elements) {
where T is a type-variable:
T extends Object declared in method <T>addAll(Collection<? super T>,T...)Du fait de la crÃĐation possible d'un tableau de type paramÃĐtrÃĐ, le dÃĐveloppeur doit prendre en charge la responsabilitÃĐ du typage, car cela ne peut pas Être assurÃĐ par le compilateur. Pour cela il faut d'abord respecter quelques rÃĻgles :
- il ne faut pas caster le tableau vers un type parent (Object[] ou autres)Â ;
- il ne faut pas modifier les ÃĐlÃĐments du tableau, puisque le paramÃĐtrage pourrait alors Être incorrect ;
- il ne faut pas retourner le tableau en valeur de retour, car on ignore l'usage qui en sera fait ;
- il ne faut pas partager le tableau avec d'autres mÃĐthodes qui pourraient effectuer les actions ci-dessus.
En clair : il faut vraiment se contenter de parcourir le tableau afin de traiter ses ÃĐlÃĐments.
Si on respecte bien ces rÃĻgles, on ne risque rien, et on peut alors apposer sur la mÃĐthode l'annotation @SafeVarargs afin de l'indiquer au compilateur, qui supprimera alors tout warning.
@SafeVarargs
public static <T> boolean addAll(Collection<? super T> c, T... elements) {
boolean result = false;
for (T element : elements)
result |= c.add(element);
return result;
}Comme on se contente bien de parcourir les divers ÃĐlÃĐments du tableau, on peut utiliser l'annotation @SafeVarargs qui nous ÃĐpargnera de tout warning à la compilation, que ce soit le "possible heap pollution" sur la mÃĐthode, ou les "unchecked generic array creation" lorsqu'on l'appellera...
L'annotation @SafeVarargs est avant tout un simple marqueur. Le compilateur ne peut pas vÃĐrifier que vous l'utilisez correctement, et il est donc impÃĐratif de respecter les rÃĻgles ci-dessus et de se contenter de parcourir les ÃĐlÃĐments du tableau gÃĐnÃĐrÃĐ par l'ellipse, sous peine d'introduire des bogues qui pourraient Être trÃĻs difficiles à dÃĐceler !
Attention : l'annotation SafeVarargs ne peut s'appliquer que sur une mÃĐthode static, une mÃĐthode final ou un constructeur. Elle ne peut pas s'appliquer sur une mÃĐthode virtuelle car rien ne peut garantir que ses redÃĐfinitions respecteront bien ces rÃĻgles...
Gestion automatique des ressources (try-with-resources)▲
Contrairement à la mÃĐmoire qui est gÃĐrÃĐe automatiquement par le Garbage Collector, il existe plusieurs types de ressources qui doivent Être gÃĐrÃĐes manuellement. C'est-à -dire qu'elles doivent Être libÃĐrÃĐes explicitement, gÃĐnÃĐralement par un appel à la mÃĐthode close(). C'est le cas par exemple de toutes les ressources gÃĐrÃĐes par le systÃĻme d'exploitation (fichiers, sockets) et assimilÃĐs (connexion JDBC?).
Le fait d'omettre de libÃĐrer les ressources peut avoir diverses consÃĐquences. Elles pourraient Être bloquÃĐes et rendues inaccessibles pour d'autres process, ou encore provoquer une utilisation abusive inutile.
Bien sÃŧr gÃĐnÃĐralement le mÃĐcanisme de finalisation de Java est utilisÃĐ pour mettre en place un garde-fou qui libÃĐrera la ressource une fois l'instance nettoyÃĐe par le GC. Mais cela se rÃĐvÃĻle insuffisant pour plusieurs raisons :
- on ne peut pas prÃĐvoir le moment exact oÃđ la ressource sera libÃĐrÃĐe, ce qui peut bloquer d'autres traitements ou programmes, voire mÊme atteindre des limites imposÃĐes par l'OS (en particulier dans une application serveur) ;
- bien souvent, l'instance de l'objet Java est insignifiante vis-Ã -vis des donnÃĐes mises en place par la ressource. Le GC n'aura donc pas forcÃĐment besoin de libÃĐrer la mÃĐmoire alors qu'il serait prÃĐfÃĐrable de libÃĐrer la ressource au plus tÃīt.
Pour pallier cela, et libÃĐrer la ressource au plus tÃīt, on utilise gÃĐnÃĐralement un bloc try/finally par ressource, afin d'y appeler explicitement chaque mÃĐthode close(), de la maniÃĻre suivante :
Res r = ... // 1. CrÃĐation de la ressource
try {
// 2. Utilisation de la ressource
...
} finally {
// 3. Fermeture de la ressource
r.close();
}Par exemple pour une copie de fichier cela nous donne quelque chose comme ceci :
try {
InputStream input = new FileInputStream(in.txt);
try {
OutputStream output = new FileOutputStream(out.txt);
try {
byte[] buf = new byte[8192];
int len;
while ( (len=input.read(buf)) >=0 )
output.write(buf, 0, len);
} finally {
output.close();
}
} finally {
input.close();
}
} catch (IOException e) {
System.err.println("Une erreur est survenue lors de la copie");
e.printStrackTrace();
}Mais cela n'est pas sans dÃĐfauts. PremiÃĻrement cela pollue ÃĐnormÃĐment le code : la libÃĐration des ressources correspond à la moitiÃĐ du code puisque chaque ressource doit Être associÃĐe à un bloc try/finally ce qui peut amener à avoir plusieurs blocs d'indentation. De mÊme pour un traitement des erreurs efficace on doit utiliser un bloc try/catch supplÃĐmentaire, sous peine de ne pas intercepter toutes les exceptions...
Mais il y a ÃĐgalement des limites à cela puisque les libÃĐrations des ressources peuvent ÃĐgalement gÃĐnÃĐrer des exceptions. Mais dans ce cas, seule la derniÃĻre exception gÃĐnÃĐrÃĐe sera remontÃĐe et les exceptions qui auraient ÃĐtÃĐ gÃĐnÃĐrÃĐes plus tÃīt seront perdues, ce qui peut fausser le problÃĻme initial et rendre plus dÃĐlicate sa rÃĐsolution.
En pratique ce problÃĻme d'exception perdue se rÃĐvÃĻle quand mÊme assez rare, et ce modÃĻle du try/finally est recommandÃĐ pour les codes prÃĐ-Java 7...
Le try-with-resources vient pallier tous ces problÃĻmes via une nouvelle syntaxe plus simple. Les ressources dÃĐclarÃĐes dans un try() seront automatiquement libÃĐrÃĐes à la fin du bloc correspondant, quoi qu'il arrive. Le code prÃĐcÃĐdent pourra dÃĐsormais s'ÃĐcrire de la maniÃĻre suivante :
try (InputStream input = new FileInputStream(in.txt);
OutputStream output = new FileOutputStream(out.txt)) {
byte[] buf = new byte[8192];
int len;
while ( (len=input.read(buf)) >=0 )
output.write(buf, 0, len);
} catch (IOException e) {
System.err.println("Une erreur est survenue lors de la copie");
e.printStrackTrace();
}On peut noter que le try-with-resources accepte plusieurs dÃĐclarations de ressources (sÃĐparÃĐes par des points-virgules), et qu'il est donc inutile de les imbriquer. La fermeture des ressources sera bien gÃĐrÃĐe mÊme en cas d'erreur lors de la crÃĐation de l'une d'entre elles. On peut facilement lui accoler un bloc catch permettant de bien capturer toutes les exceptions, que ce soit lors de la crÃĐation des ressources, de leur utilisation ou de leur libÃĐration...
De mÊme le problÃĻme des exceptions perdues est gÃĐrÃĐ correctement : si le code a dÃĐjà gÃĐnÃĐrÃĐ une exception, les suivantes seront ajoutÃĐes directement dans son stacktrace via un nouveau mÃĐcanisme intÃĐgrÃĐ dans la classe Throwable via la mÃĐthode addSuppressed(). Ainsi aucune exception n'est perdue !
Il faut malgrÃĐ tout continuer de se mÃĐfier des encapsulations de flux. En effet si l'un des flux gÃĐnÃĻre une exception, le flux qu'il encapsule ne sera pas visible par le try-with-resources et il ne pourra donc pas Être fermÃĐ correctement :
// DANGER car new ObjectInputStream() peut gÃĐnÃĐrer une IOException si le fichier est mal formÃĐ.
// Dans ce cas le FileInputStream ne pourra pas Être fermÃĐ :
try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream("file"))) {
...
}On peut ÃĐviter cela en sÃĐparant bien les diffÃĐrents flux. Ils seront alors bien ouverts dans l'ordre de dÃĐclaration, puis correctement fermÃĐs dans l'ordre inverse :
// OK car le fichier sera bien fermÃĐ mÊme en cas d'exception sur l'ObjectInputStream :
try (FileInputStream fis = new FileInputStream("file");
ObjectInputStream ois = new ObjectInputStream(fis)) {
...
}Le try-with-ressources ne peut Être utilisÃĐ qu'avec des instances d'objets implÃĐmentant la nouvelle interface java.lang.AutoCloseable. Cette derniÃĻre se contente de dÃĐfinir la mÃĐthode close() throws Exception qui sera utilisÃĐe pour libÃĐrer la ressource.
L'interface existante java.io.Closeable n'a pas pu Être utilisÃĐe pour cela à cause de sa mÃĐthode close() trop spÃĐcifique (elle utilise une IOException). Mais elle ÃĐtend dÃĐsormais d'AutoCloseable ce qui permet d'utiliser le try-with-ressources avec tous les flux d'entrÃĐes/sorties.
L'utilisation d'AutoCloseable permet ainsi de gÃĐnÃĐraliser cela à tout type d'ÃĐlÃĐment plus variÃĐ. Toute classe possÃĐdant une mÃĐthode void close() peut donc implÃĐmenter AutoCloseable, qu'elle dÃĐclare une exception ou pas. C'est le cas par exemple les ressources JDBC qui utilisent des SQLExceptions (Connection, Statement, ResultSet...), ou encore les ressources liÃĐs à l'API Audio javax.sound dont la fermeture ne gÃĐnÃĻre aucune exception (Line, MidiDevice, etc.).
Java 7 introduit ainsi un nouveau concept, les "Suppressed Exceptions", afin de gÃĐrer proprement les multiples exceptions qui peuvent survenir lors de la fermeture des flux. Si ces derniÃĻres surviennent alors qu'une exception est dÃĐjà en train de remonter, elles seront "ajoutÃĐes" à l'exception originale via addSuppressed() au lieu de la remplacer, ce qui permet d'ÃĐviter de perdre de l'information (elles seront bien visibles dans le stacktrace).
Multicatch : traiter plus d'une exception à la fois▲
Il est dÃĐsormais possible d'intercepter plus d'une exception à la fois dans le mÊme bloc catch, ce qui permet d'ÃĐviter les duplications de code.
try {
...
} catch(IOException e) {
// traitement
} catch(SQLException e) {
// traitement
}Si les traitements sont identiques, le code ci-dessus peut dÃĐsormais s'ÃĐcrire en utilisant un seul et unique bloc catch, de la maniÃĻre suivante :
try {
...
} catch(IOException | SQLException e) {
// traitement
}Il est possible de rajouter autant de types d'exception que l'on souhaite, en les sÃĐparant via le caractÃĻre pipe |. Le type de l'exception à l'intÃĐrieur du bloc catch correspond au type parent commun le plus proche (soit Exception dans ce cas prÃĐcis).
à noter que le bytecode ainsi gÃĐnÃĐrÃĐ sera ÃĐgalement plus performant du fait qu'il n'y aura aucune duplication du code de traitement.
AmÃĐlioration du rethrow▲
Le rethrow n'est pas un nouveau concept en soi, puisque cela consiste simplement à remonter une exception aprÃĻs l'avoir catchÃĐe, comme dans le code suivant :
public void method() throws Exception {
try {
// code qui remonte uniquement des IOException ou SQLException...
} catch (Exception e) {
// traitement
throw e; // throws Exception
}
}L'intÃĐrÊt consiste à pouvoir effectuer certains traitements en cas d'exception (logger, rÃĐinitialiser des champs, etc.) tout en laissant remonter l'exception à un niveau plus haut (afin de permettre son traitement).
Comme dans la plupart des langages, le rethrow est trÃĻs basique : le type d'exception remontÃĐe correspond simplement au type dÃĐclarÃĐ de la variable. Mais, à l'inverse de la plupart des langages, Java utilise un mÃĐcanisme de vÃĐrification des exceptions (les checked-exceptions). Et ça change tout ! En effet le code ci-dessus dÃĐclarera remonter n'importe quelle Exception, alors qu'en rÃĐalitÃĐ ce ne pourrait Être uniquement qu'une IOException, une SQLException ou n'importe quelle "unchecked-exception" (RuntimeException ou Error, qui peuvent toujours Être remontÃĐes sans avoir à Être dÃĐclarÃĐes).
Avec Java 7, le rethrow a donc ÃĐtÃĐ affinÃĐ afin de mieux correspondre à la rÃĐalitÃĐ. C'est-à -dire que le type d'exception remontÃĐe dÃĐpend ÃĐgalement du type d'exception pouvant Être remontÃĐe par le bloc try, et donc d'obtenir une clause throws bien plus prÃĐcise, ce qui ÃĐvite de polluer la clause throws de la mÃĐthode :
public void method() throws IOException, SQLException {
try {
// code qui remonte uniquement des IOException ou SQLException...
} catch (Exception e) {
// traitement
throw e; // throws IOException, SQLException (ou une unchecked exception)
}
}En toute logique, le rethrow ne peut fonctionner que si la variable "e" du catch n'est pas modifiÃĐe dans le bloc catch. Elle doit Être implicitement final.
JSR 292 - Support des langages dynamiques (invokedynamic)▲
Bien que le langage Java soit prÃĐdominant, la plateforme Java peut accepter tout type de langage à partir du moment oÃđ il est compilÃĐ en bytecode Java. Parmi les langages les plus populaires, on retrouve ainsi Groovy, Scala, JRuby, Jython et d'autres...
Mais le langage Java est fortement typÃĐ, et tous les appels de mÃĐthode sont vÃĐrifiÃĐs par le compilateur, afin de dÃĐtecter un maximum d'erreurs au plus tÃīt. En Java il est ainsi impossible d'appeler une mÃĐthode qui n'existe pas dans le type dÃĐclarÃĐ. Et jusqu'Ã prÃĐsent, le bytecode Java s'alignait tout logiquement sur ce fonctionnement.
Toutefois, les langages de scripts sont gÃĐnÃĐralement plus souples en proposant un typage faible. C'est-à -dire que les variables ne sont pas typÃĐes ou faiblement typÃĐes, et que du coup il est possible d'appeler n'importe quelle mÃĐthode sans vÃĐrification lors de la compilation. Ce n'est que lors de l'exÃĐcution que tout ceci sera vÃĐrifiÃĐ. Mais comme le bytecode Java n'offrait aucune facilitÃĐ pour gÃĐrer ces appels de mÃĐthodes dynamiques, la plupart de ces langages devaient donc simuler cela, gÃĐnÃĐralement en gÃĐnÃĐrant un appel de mÃĐthode static et en utilisant la reflection pour rechercher la mÃĐthode à exÃĐcuter.
Une API pour rechercher des ÃĐlÃĐments▲
Pour commencer, l'API standard s'enrichit d'un nouveau package java.lang.invoke, qui apporte toutes les notions relatives à l'invocation dynamique. Elle permet principalement de rechercher des ÃĐlÃĐments du langage (mÃĐthodes, constructeurs, attributs) afin de les associer à un handle. Ce dernier permettra d'exÃĐcuter le code correspondant. De prime abord cela semble assez proche de l'API de reflection, il en est toutefois assez distinct sur de nombreux points.
Tout d'abord, chaque ÃĐlÃĐment est typÃĐ via la classe MethodType, qui dÃĐcrit à la fois le type de la valeur de retour et le type de chacun de ses paramÃĻtres. On dispose de mÃĐthode static nous permettant de crÃĐer facilement un MethodType :
// MÃĐthode avec deux paramÃĻtres (String,int) retournant un int :
// Le premier paramÃĻtre correspond au type de retour,
// Les paramÃĻtres suivants correspondent aux types des paramÃĻtres, dans l'ordre
MethodType type = MethodType.methodType(int.class, String.class, int.class);Cette nouvelle API nous permet donc de crÃĐer des MethodHandle, ce qui correspond en quelque sorte à un pointeur de fonction. Pour cela nous devrons utiliser un objet Lookup permettant de rechercher ces divers ÃĐlÃĐments.
MethodHandles.Lookup lookup = MethodHandles.lookup();Contrairement à l'API de reflection, l'API d'invocation dynamique respecte les rÃĻgles de visibilitÃĐ du langage. C'est-à -dire que ce Lookup dispose des mÊmes rÃĻgles d'accÃĻs que le code qui l'a instanciÃĐ. Il peut donc retrouver :
- tous les ÃĐlÃĐments public de n'importe quelle classe visible ;
- tous les ÃĐlÃĐments protected des classes parentes ;
- tous les ÃĐlÃĐments protected ou package-view des classes du mÊme package ;
- tous les ÃĐlÃĐments private de sa propre classe.
Mais il est ÃĐgalement possible que le Lookup public nous permette de rechercher uniquement les ÃĐlÃĐments public depuis n'importe quelle classe :
MethodHandles.Lookup lookup = MethodHandles.publicLookup();Les Lookups nous permettent donc de crÃĐer des MÃĐthodHandles associÃĐs à un ÃĐlÃĐment quelconque d'une classe (mÃĐthode, constructeur ou attribut).
Par exemple pour recherche une mÃĐthode d'instance, on utilisera findVirtual(), qui attend trois paramÃĻtres :
- la classe (Class)Â ;
- le nom de la mÃĐthode (String)Â ;
- le type de la mÃĐthode (MethodType).
// boolean contains(CharSequence) de la classe String :
MethodHandle contains = lookup.findVirtual(String.class, "contains",
MethodType.methodType(boolean.class, CharSequence.class) );Puisqu'il s'agit d'une mÃĐthode d'instance, le type du MethodHandle correspond à celui de la mÃĐthode à laquelle on aura insÃĐrÃĐ le type de la classe en premier paramÃĻtre.
Il est ÃĐgalement possible de rÃĐcupÃĐrer un handle sur un constructeur via findConstructor(). Ici le nom du constructeur est logiquement inutile. De mÊme les constructeurs n'ayant pas de type de retour, on utilisera par convention le type void :
// Constructeur Date()
MethodHandle constructor = lookup.findConstructor(java.util.Date.class,
MethodType.methodType(void.class));Dans le cas d'un constructeur, c'est le type de retour qui est modifiÃĐ afin de correspondre à celui du type crÃĐÃĐ par le constructeur.
Les attributs peuvent ÃĐgalement Être la cible d'un MethodHandle, en lecture ou en ÃĐcriture. On se contentera alors de prÃĐciser le nom et le type de l'attribut :
// Attribut Point.x en lecture :
MethodHandle readX = lookup.findGetter(java.awt.Point.class,
"x", int.class);
// Attribut Point.x en lecture :
MethodHandle writeX = lookup.findSetter(java.awt.Point.class,
"x", int.class);Attention : les handles ainsi crÃĐÃĐs accÃĻdent directement à l'attribut sans passer par une ÃĐventuelle mÃĐthode getter/setter. Si on a besoin de ce comportement il faut passer par findVirtual().
Il est mÊme possible d'utiliser findSpecial() pour retrouver certaines mÃĐthodes spÃĐciales, comme les mÃĐthodes parentes que l'on a redÃĐfinies (que l'on appellerait gÃĐnÃĐralement via super.method()). On utilise dans ce cas un quatriÃĻme paramÃĻtre correspondant au type fils appelant :
// MÃĐthode super.toString()
MethodHandle superToString = lookup.findSpecial(Object.class, "toString",
MethodType.methodType(String.class), MyClasse.class);On dispose ÃĐgalement des mÃĐthodes findStatic(), findStaticGetter() et findStaticSetter() afin de retrouver une mÃĐthode ou un attribut static. Sans oublier les mÃĐthodes unreflect*() permettant d'obtenir un MethodHandle à partir d'un ÃĐlÃĐment de l'API de reflection.
MethodHandle, le pointeur de fonction▲
Les objets de type MethodHandle ainsi crÃĐÃĐs correspondent à une sorte de pointeur de fonction, et permettent donc d'exÃĐcuter le code correspondant. On dispose pour cela de la mÃĐthode invokeExact(), qui doit Être appelÃĐe en utilisant les types exacts associÃĐs au handle :
// boolean contains(CharSequence) de la classe String :
MethodHandle contains = MethodHandles.publicLookup().findVirtual(
String.class, "contains",
MethodType.methodType(boolean.class, CharSequence.class) );
// Ãquivalent de : "Java7".contains("Java")
boolean result = (boolean)contains.invokeExact("Java 7", (CharSequence)"Java");La mÃĐthode contains() de la classe String retourne un boolean, il est donc impÃĐratif de caster vers ce type prÃĐcis. De mÊme son premier paramÃĻtre ÃĐtant l'interface CharSequence, il est impÃĐratif de caster le paramÃĻtre vers ce type afin que la signature de l'appel corresponde exactement au type associÃĐ au MethodHandle. Si les types dÃĐclarÃĐs sont diffÃĐrents, il est impÃĐratif de les caster vers le type appropriÃĐ.
Attention : si on ne respecte pas le type exact du MethodHandle, l'utilisation d'invokeExact() engendrera une exception. Et ceci mÊme si les types sont compatibles.
Il est ÃĐgalement possible d'utiliser la mÃĐthode invoke(), plus souple dans le sens oÃđ elle vÃĐrifiera la compatibilitÃĐ des types et qu'elle s'occupera des ÃĐventuelles conversions.
// => throws WrongMethodTypeException
boolean result = (boolean)contains.invokeExact("Java 7", "Java");
// => OK
boolean result = (boolean)contains.invoke("Java 7", "Java");Attention : les mÃĐthodes invokeExact() et invoke() bÃĐnÃĐficient d'un traitement particulier de la part du compilateur et de la JVM. De ce fait, il est impÃĐratif d'utiliser un compilateur bien qu'elles soient dÃĐclarÃĐes avec une ellipse d'objet (varargs), à la compilation elle gÃĐnÃĻre une instruction correspondant à la signature des paramÃĻtres qu'on lui passe. Ceci permet de vÃĐrifier les types à l'exÃĐcution.
Et c'est là qu'on retrouve la premiÃĻre grosse diffÃĐrence entre l'API de reflection et l'API d'invocation dynamique. Avec l'API de reflection, les rÃĻgles de visibilitÃĐ sont vÃĐrifiÃĐes à chaque appel de mÃĐthode. Avec les MethodHandles, ces vÃĐrifications sont effectuÃĐes par le Lookup lors de la recherche de l'ÃĐlÃĐment, mais pas lors de son appel. Cela signifie qu'il est possible de partager un MethodHandle sans que cela pose de problÃĻme de droit d'accÃĻs.
La seconde grosse diffÃĐrence vient du fait que l'on peut associer un MethodHandle à une instance. Le premier paramÃĻtre sera alors automatiquement passÃĐ Ã chaque appel, et le type associÃĐ au handle sera donc modifiÃĐ en consÃĐquence (il perdra son premier paramÃĻtre) :
// boolean contains(CharSequence) de la classe String :
MethodHandle contains = MethodHandles.publicLookup().findVirtual(
String.class, "contains",
MethodType.methodType(boolean.class, CharSequence.class) );
System.out.println(contains); // MethodHandle(String,CharSequence)boolean
// On associe le handle à une instance :
contains = contains.bindTo("Java 7");
System.out.println(contains); // MethodHandle(CharSequence)boolean
// Ce qui nous permet d'appeler le handle directement :
boolean result = (boolean)contains.invokeExact((CharSequence)"Java");
// Equivalent de : "Java 7".contains("Java")Plus intÃĐressant : la classe utilitaire MethodHandles comporte plusieurs mÃĐthodes static permettant de modifier les MethodHandles. Quelques exemples :
- insertArguments() permet de spÃĐcifier la valeur des arguments avant l'invocation du handle. Ceci est similaire à la mÃĐthode bindTo() si ce n'est que l'on prÃĐcise l'index du paramÃĻtre à associer, et que l'on peut en associer plusieurs ;
- dropArguments() permet de rajouter des paramÃĻtres fantÃīmes. C'est-à -dire qu'ils seront ajoutÃĐs au type du handle, mais qu'ils seront ignorÃĐs lors de l'appel ;
- permuteArguments() permet de modifier l'ordre des paramÃĻtres, en prÃĐcisant le nouveau type ainsi que l'ordre des paramÃĻtres ;
- filterArguments() et filterReturnValue() permettent de filtrer les valeurs des paramÃĻtres (avant l'appel de mÃĐthode) ou de la valeur de retour (aprÃĻs l'exÃĐcution de la mÃĐthode).
- ...
// boolean contains(CharSequence) de la classe String :
MethodHandle contains = MethodHandles.publicLookup().findVirtual(
String.class, "contains",
MethodType.methodType(boolean.class, CharSequence.class) );
System.out.println(contains); // MethodHandle(String,CharSequence)boolean
contains = MethodHandles.permuteArguments(contains,
MethodType.methodType(boolean.class, CharSequence.class, String.class),
1, 0 // Le nouvel index des paramÃĻtres
);
System.out.println(contains); // MethodHandle(CharSequence,String)boolean
// Ãquivalent de : "Java7".contains("Java")
boolean result = (boolean)contains.invokeExact((CharSequence)"Java", "Java 7");Toutes ces mÃĐthodes permettent d'adapter le type associÃĐ Ã un handle, afin de l'adapter à une signature spÃĐcifique. Par exemple il est possible de transformer un MethodHandle en une interface compatible, c'est-à -dire une interface contenant une seule et unique mÃĐthode abstraite (SAM - Single Abstract Method), et dont la signature correspond au type du MethodHandle :
MethodHandle handle = MethodHandles.publicLookup().findVirtual(
String.class, "compareToIgnoreCase",
MethodType.methodType(int.class, String.class));
Comparator<?> compareToIgnoreCase =
MethodHandleProxies.asInterfaceInstance(Comparator.class, handle);Et l'invocation dynamique ?▲
L'invocation dynamique n'est pas supportÃĐe par le langage Java, mais uniquement dans le bytecode. C'est-Ã -dire qu'il n'est pas possible de l'utiliser directement dans une application Java. Il faut que ce soit implÃĐmentÃĐ par un des divers langages dynamiques basÃĐs sur une JVM.
L'instruction invoquedynamic n'est donc pas liÃĐe à une mÃĐthode existante. Au lieu de cela elle est liÃĐe à une mÃĐthode dite de bootstrap dont le rÃīle sera de dÃĐterminer le code qui devra Être exÃĐcutÃĐ Ã l'exÃĐcution. Elle dispose pour cela d'informations sur l'appel en question (le Lookup du code appelant, ainsi que le nom et le type de la mÃĐthode), ainsi que d'ÃĐventuels paramÃĻtres spÃĐcifiques.
Rappel : le langage Java ne permet toujours pas d'utiliser l'invocation dynamique. Cette section concerne principalement l'implÃĐmentation d'un langage dynamique sur une JVM. L'instruction invoquedynamic doit donc Être gÃĐrÃĐe spÃĐcifiquement par ces langages dynamiques.
L'instruction invoquedynamic ne peut pas Être vÃĐrifiÃĐe par le compilateur, puisque la cible n'est pas connue au moment de l'exÃĐcution. Au lieu de cela, elle comporte un lien vers une mÃĐthode de bootstrap. Cette mÃĐthode a pour rÃīle de dÃĐterminer le code qui devra Être exÃĐcutÃĐ Ã l'exÃĐcution. Elle dispose pour cela des informations de l'appel : le Lookup du code appelant, le nom et le type de la mÃĐthode.
Pour prendre un exemple basique, dans le code ci-dessous, la mÃĐthode de bootstrap renvoie un handle vers une mÃĐthode static d'une classe utilitaire.
static CallSite bootstrap(MethodHandles.Lookup caller, String name, MethodType type)
throws ReflectiveOperationException {
return new ConstantCallSite( caller.findStatic(UtilityClass.class, name, type) );
}L'intÃĐrÊt, c'est que cette mÃĐthode de bootstrap ne sera appelÃĐe qu'une seule fois pour toutes les signatures strictement identiques, et que tous les appels suivants s'effectueront directement sans exÃĐcuter la mÃĐthode de bootstrap. Mieux : la JVM pourra alors effectuer toutes sortes d'optimisations comme l'inlining, comme c'est dÃĐjà le cas pour les appels de mÃĐthodes classiques (mais ce qui n'est pas possible avec la reflection).
Ainsi, les langages dynamiques peuvent dÃĐsormais se contenter d'implÃĐmenter des mÃĐthodes de bootstrap qui se chargeront de dÃĐterminer le code à exÃĐcuter lors de l'exÃĐcution (bien sÃŧr dans le cas d'un langage dynamique ces mÃĐthodes de bootstrap risquent de se rÃĐvÃĐler plus complexes).
Usage et performance▲
L'API d'invocation dynamique n'a pas vraiment vocation à Être utilisÃĐe directement par la majoritÃĐ des dÃĐveloppeurs Java, puisque son principal intÃĐrÊt reste la possibilitÃĐ d'implÃĐmenter plus facilement et plus efficacement un langage dynamique en profitant des avantages de la JVM.
De ce cÃītÃĐ-là le pari semble rÃĐussi puisque grÃĒce au "bootstrap", la recherche de la mÃĐthode à exÃĐcuter ne s'effectue plus que lors du premier appel, tout en bÃĐnÃĐficiant par la suite de toutes les ÃĐventuelles optimisations de la JVM (comme l'inlining entre autres). Mais il faudra quand mÊme du temps avant d'en profiter rÃĐellement. En effet si les divers langages dynamiques basÃĐs sur une JVM ont commencÃĐ Ã intÃĐgrer cela (avec une amÃĐlioration des performances à la clef), ils conservent toujours leur prÃĐcÃĐdent fonctionnement afin de rester compatibles avec la majoritÃĐ des JVM.
Pour le dÃĐveloppeur Java, elle ne s'avÃĻre pas particuliÃĻrement intÃĐressante vis-à -vis de l'API Reflection, mÊme si elle apporte quelques concepts diffÃĐrents. En effet si les MethodHandles permettent en thÃĐorie de meilleures performances, leur implÃĐmentation actuelle est loin de rivaliser avec les multiples optimisations de l'API de Reflection que l'on a pu avoir au cours des derniÃĻres annÃĐes...
Mais cela pourrait Être amenÃĐ Ã ÃĐvoluer rapidement...
JSR 203 - NIO.2 : accÃĻs complet aux systÃĻmes de fichiers▲
Java 7 introduit un nouveau package java.nio.file en remplacement de la classe java.io.File.
- Une gestion propre des exceptions.
La plupart des mÃĐthodes de la classe File se contentent de renvoyer une valeur nulle en cas d'ÃĐchec du traitement, et de ce fait il est parfois difficile d'en cibler l'origine. - Un accÃĻs complet au systÃĻme de fichiers, avec le support de fonctionnalitÃĐs absentes jusque-là comme le support des attributs spÃĐcifiques au systÃĻme (Unix, DOS, droits d'accÃĻs ACL...), le support des liens/liens symboliques, etc.
- L'ajout de la notion de FileSystem (le systÃĻme de fichiers) et du FileStore reprÃĐsentant le support (par exemple une partition du disque). Le tout de maniÃĻre abstraite et ÃĐvolutive.
- L'ajout de mÃĐthodes utilitaires, afin de ne plus rÃĐinventer la roue (dÃĐplacement/copie de fichier, lecture/ÃĐcriture binaire ou texte, parcours d'une arborescence via des visiteurs).
- De meilleures implÃĐmentations, comme les DirectoryStream qui permettent de rÃĐcupÃĐrer la liste des fichiers d'un rÃĐpertoire via un flux, en ÃĐvitant ainsi de tous les charger en mÃĐmoire comme c'est le cas des mÃĐthodes File.list() et File.listFiles() (ce qui peut s'avÃĐrer problÃĐmatique si l'on parcourt de gros rÃĐpertoires).
java.nio.file.Path remplacera java.io.File▲
La classe java.io.File est donc vouÃĐe à disparaÃŪtre, au profit de l'interface java.nio.file.Path. Cette derniÃĻre dÃĐcrit donc un chemin associÃĐ Ã un systÃĻme de fichiers. Mais contrairement à File, Path comporte principalement des mÃĐthodes de manipulation du chemin.
On obtient normalement un objet Path en passant par un objet FileSystem reprÃĐsentant le systÃĻme de fichiers. Toutefois, dans la plupart des cas on utilisera la mÃĐthode Paths.get() pour utiliser directement le systÃĻme de fichiers par dÃĐfaut de l'OS hÃīte...
// Avec java.io.File
File file = new File("file.txt");
// Avec java.nio.file.Path :
Path path = FileSystems.getDefault().getPath("file.txt");
// Avec java.nio.file.Path :
Path path = Paths.get("file.txt");Si la java.nio.file.Path devait Être privilÃĐgiÃĐe dans les futures API, la classe java.io.File n'est toutefois pas dÃĐprÃĐciÃĐe du fait de sa large utilisation. Afin de faciliter la coexistence de code utilisant l'une ou l'autre, nous disposons des mÃĐthodes toPath() et toFile() permettant de passer facilement d'un type à l'autre.
à noter que les mÃĐthodes de crÃĐation d'un Path acceptent un nombre d'arguments variables, permettant de juxtaposer plusieurs bouts du chemin final reprÃĐsentÃĐ par ce Path. Tout comme java.io.File, on peut utiliser le sÃĐparateur / quel que soit le systÃĻme, mais l'objet Path ainsi crÃĐÃĐ contiendra toujours le bon sÃĐparateur.
Path path = Paths.get("/chemin/de/base", "sous-rÃĐpertoire", "encore/plusieurs/rÃĐpertoires", "file.txt");Files : mÃĐthodes à tout faire▲
Path ne comporte aucune mÃĐthode d'accÃĻs aux informations sur les fichiers, ni aucune des mÃĐthodes utilitaires que l'on pouvait trouver dans la classe java.io.File. Toutes ces mÃĐthodes se retrouvent dÃĐportÃĐes dans des mÃĐthodes static d'une classe utilitaires Files.
Path path = Paths.get("file.txt");
boolean exists = Files.exists(path);
boolean isDirectory = Files.isDirectory(path);
boolean isExecutable = Files.isExecutable(path);
boolean isHidden = Files.isHidden(path);
boolean isReadable = Files.isReadable(path);
boolean isRegularFile = Files.isRegularFile(path);
boolean isWritable = Files.isWritable(path);
long size = Files.size(path);
FileTime time = Files.getLastModifiedTime(path);
Files.delete(path);Et la raison est toute simple : contrairement à java.io.File qui ne peut reprÃĐsenter qu'un fichier sur le systÃĻme de fichiers de l'OS, le type Path correspond à un chemin sur un systÃĻme de fichiers quelconque. Bien sÃŧr par dÃĐfaut (via Paths.get()), cela correspond bien à un fichier sur le systÃĻme de fichiers de l'OS. Mais l'API offre la possibilitÃĐ de crÃĐer d'autres systÃĻmes de fichiers, et d'y associer des Paths, qui pourraient trÃĻs bien offrir d'autres possibilitÃĐs.
L'usage voudrait donc de passer par le provider du systÃĻme de fichiers pour accÃĐder aux informations (car chaque systÃĻme de fichiers pourrait proposer ses propres spÃĐcificitÃĐs). La classe Files propose donc des mÃĐthodes utilitaires pour simplifier cela.
On notera ÃĐgalement l'apparition de plusieurs fonctionnalitÃĐs bien pratiques, mais absentes jusque-là de l'API standard :
Files.copy(Paths.get("source.txt"), Paths.get("dest.txt"));
Files.copy(Paths.get("source.txt"), Paths.get("dest.txt"),
StandardCopyOption.REPLACE_EXISTING,
StandardCopyOption.COPY_ATTRIBUTES
); Files.move(Paths.get("source.txt"), Paths.get("dest.txt"));
Files.move(Paths.get("source.txt"), Paths.get("dest.txt"),
StandardCopyOption.REPLACE_EXISTING,
StandardCopyOption.COPY_ATTRIBUTES,
StandardCopyOption.ATOMIC_MOVE
); Path path = ...
byte[] byteArray = Files.readAllBytes(path);
Files.write(path, byteArray); Path path = ...
Charset charset = ...
List<String> lines = Files.readAllLines(path, charset);
Files.write(path, lines, charset); Path link = ...
Path existing = ...
Files.createLink(link, existing);
Files.createSymbolicLink(link, existing); Path path = ...
String contentType = Files.probeContentType(path); // Ouverture en lecture :
try ( InputStream input = Files.newInputStream(path) ) {
...
}
// Ouverture en ÃĐcriture :
try ( OutputStream output = Files.newOutputStream(path) ) {
...
}
// Ouverture d'un Reader en lecture :
try ( BufferedReader reader = Files.newBufferedReader(path, StandardCharsets.UTF_8) ) {
...
}
// Ouverture d'un Writer en ÃĐcriture :
try ( BufferedWriter writer = Files.newBufferedWriter(path, StandardCharsets.UTF_8) ) {
...
}Les mÃĐthodes permettant d'ouvrir un fichier acceptent des paramÃĻtres de type OpenOption via une ellipse. Ce type correspond à une interface dont les valeurs possibles sont dÃĐfinies par l'enum StandardOpenOption, qui apporte entre autres des options avancÃĐes comme l'utilisation des "sparse file" (fichiers contenant des espaces vides qui ne seront pas ÃĐcrits sur le disque) ou la possibilitÃĐ de forcer la synchronisation de l'ÃĐcriture des donnÃĐes...
Files.write(path, data,
StandardOpenOption.APPEND,
StandardOpenOption.SPARSE,
StandardOpenOption.SYNC);Les mÃĐthodes permettant une copie de fichier acceptent des paramÃĻtres de type CopyOption via une ellipse. Ce type correspond à une interface dont les valeurs possibles sont dÃĐfinies par l'enum StandardCopyOption permettant de configurer les options de copie.
Files.copy(path1, path2,
StandardCopyOption.ATOMIC_MOVE,
StandardCopyOption.COPY_ATTRIBUTES,
StandardCopyOption.REPLACE_EXISTING);Plusieurs de ces mÃĐthodes acceptent un paramÃĻtre supplÃĐmentaire de type LinkOption. Ce type correspond à une enum ne contenant qu'une seule valeur NOFOLLOW_LINKS qui permet de ne pas suivre les liens symboliques lorsqu'on la passe à une mÃĐthode (les liens sont toujours suivis par dÃĐfaut). Cette enum LinkOption implÃĐmente ÃĐgalement les interfaces OpenOption et CopyOption, ce qui nous permet ÃĐgalement de l'utiliser dans ces cas-là .
// Copie d'un fichier :
Files.copy(path1, path2);
// Copie d'un lien symbolique :
Files.copy(path1, path2,
StandardCopyOption.REPLACE_EXISTING,
LinkOption.NOFOLLOW_LINKS);DirectoryStream : lister les ÃĐlÃĐments d'un dossier▲
La classe Files permet ÃĐgalement de lister les fichiers d'un rÃĐpertoire. Mais à la diffÃĐrence de java.io.File ce listing se fait via un flux/Iterator, ce qui nous ÃĐvite de charger tous les rÃĐsultats en mÃĐmoire dans un tableau (spÃĐcialement utile lors du parcours de rÃĐpertoires contenant beaucoup de fichiers).
Path dir = Paths.get(); // current directory
try (DirectoryStream<Path> stream = Files.newDirectoryStream(dir)) {
for (Path path : stream) {
System.out.println(path);
}
}On notera l'utilisation du try-with-ressource permettant une libÃĐration propre du DirectoryStream.
Il est bien sÃŧr possible d'utiliser un filtre sur n'importe quel critÃĻre :
Path dir = Paths.get(); // current directory
DirectoryStream.Filter<Path> filter = new DirectoryStream.Filter<Path>() {
@Override
public boolean accept(Path entry) throws IOException {
return Files.isRegularFile(entry) && Files.size(entry) > 8192L;
}
};
try (DirectoryStream<Path> stream = Files.newDirectoryStream(dir, filter)) {
for (Path path : stream) {
System.out.println(path);
}
}Plus intÃĐressant, il est possible d'utiliser une syntaxe glob pour filtrer les fichiers selon leur nom en utilisant la syntaxe du shell.
Par exemple en utilisant *.txt pour rechercher tous les fichiers avec l'extension txt :
Path dir = Paths.get(); // current directory
try (DirectoryStream<Path> stream = Files.newDirectoryStream(dir, "*.txt")) {
for (Path path : stream) {
System.out.println(path);
}
}FileVisitor : parcours d'une arborescence▲
Autre nouveautÃĐ : la possibilitÃĐ de parcourir trÃĻs simplement une arborescence de fichiers via la mÃĐthode walkFileTree().
Path dir = Paths.get(); // current directory
Files.walkFileTree(dir, new SimpleFileVisitor<Path>() {
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs)
throws IOException {
System.out.println(file);
return FileVisitResult.CONTINUE;
}
});Par dÃĐfaut les liens symboliques ne sont pas suivis. Dans le cas inverse une dÃĐtection des cycles est intÃĐgrÃĐe afin d'ÃĐviter de tourner en rond inutilement.
Path dir = Paths.get(); // current directory
Files.walkFileTree(dir, EnumSet.of(FileVisitOption.FOLLOW_LINKS),
Integer.MAX_VALUE, new SimpleFileVisitor<Path>() {
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs)
throws IOException {
System.out.println(file);
return FileVisitResult.CONTINUE;
}
});L'interface FileVisitor dispose de quatre mÃĐthodes permettant de manipuler le dÃĐroulement du parcours. La classe SimpleFileVisitor propose une implÃĐmentation basique qui nous permet d'implÃĐmenter uniquement ce dont on a besoin.
- visitFile() est exÃĐcutÃĐe sur chaque fichier trouvÃĐ.
- visitFileFailed() ext exÃĐcutÃĐe lorsqu'une erreur empÊche l'accÃĻs au fichier.
- preVisitDirectory() est appelÃĐe avant le parcours d'un rÃĐpertoire.
- postVisitDirectory() est appelÃĐe une fois le rÃĐpertoire parcouru.
La valeur de retour de ces mÃĐthodes permet de continuer le traitement (CONTINUE), d'ignorer certains ÃĐlÃĐments (SKIP_SIBLINGS ou SKIP_SUBTREE) ou mÊme d'arrÊter le parcours (TERMINATE).
FileAttributeView : accÃĻs aux attributs▲
Un des gros points noirs de la classe java.io.File concerne l'accÃĻs aux attributs de fichiers, qui reste limitÃĐ au strict minimum. DÃĐsormais nous auront un accÃĻs complet aux attributs via un systÃĻme de vue, qui dÃĐpendront bien ÃĐvidemment du systÃĻme de fichiers hÃīte.
Nous disposons pour cela de cinq vues standards, nous permettant d'accÃĐder en lecture/ÃĐcriture à ces diffÃĐrents attributs :
- BasicFileAttributeView (basic) permet un accÃĻs aux propriÃĐtÃĐs de base, gÃĐnÃĐralement communes à tous les systÃĻmes de fichiers ;
- DosFileAttributeView (dos) ÃĐtend la premiÃĻre en y apportant le support des attributs MS-DOS (readonly, hidden, system, archive)Â ;
- PosixFileAttributeView (posix) ÃĐtend la premiÃĻre en y apportant le support des permissions POSIX du monde Unix ;
- FileOwnerAttributeView permet de manipuler le propriÃĐtaire du fichier ;
- AclFileAttributeView (acl) permet de manipuler l'Access Control Lists (ACL), c'est-à -dire les droits d'accÃĻs au fichier ;
- UserDefinedFileAttributeView (user) permet enfin de dÃĐfinir des attributs personnalisÃĐs.
Le support de ses vues dÃĐpend du systÃĻme de fichiers et de l'emplacement de stockage utilisÃĐ. Afin de vÃĐrifier le support d'une vue, on peut utiliser la mÃĐthode supportsFileAttributeView() du FileStore associÃĐ Ã notre Path.
Path path = ...
// VÃĐrification par classe :
boolean isSupported = Files.getFileStore(path).supportsFileAttributeView(DosFileAttributeView.class);
// VÃĐrification par nom :
boolean isSupported = Files.getFileStore(path).supportsFileAttributeView("dos");Lorsqu'une vue est supportÃĐe, on peut alors utiliser la mÃĐthode Files.getFileAttributeView() pour en rÃĐcupÃĐrer une instance. La vue nous permet alors d'accÃĐder ou de modifier ses attributs :
DosFileAttributeView dosView = Files.getFileAttributeView(path, DosFileAttributeView.class);
dosView.setArchive(false);
dosView.setHidden(false);
dosView.setReadOnly(false);
dosView.setSystem(false);
dosView.setTimes(lastModifiedTime, lastAccessTime, createTime);
DosFileAttributes attrs = dosView.readAttributes();
boolean a = attrs.isArchive();
boolean h = attrs.isHidden();
boolean r = attrs.isReadOnly();
boolean s = attrs.isSystem();
...La mÃĐthode readAttributes(), commune aux trois premiÃĻres vues, permet de lire tous les attributs du fichier en les retournant dans un objet. Cela permet d'ÃĐviter de multiplier les accÃĻs au systÃĻme de fichiers. On peut rÃĐcupÃĐrer ces informations directement sans passer par la vue via la mÃĐthode Files.readAttributes() :
DosFileAttributes attrs = Files.readAttributes(path, DosFileAttributes.class);
...Il est ÃĐgalement possible d'accÃĐder aux attributs via leurs noms, en les rÃĐfÃĐrençant sous la forme "view-name:attribute-name", oÃđ "view-name" correspond au nom de la vue, et "attribute-name" à celui de l'attribut (voir la javadoc des classes de ces vues pour la liste des noms des attributs, ainsi que le type de donnÃĐes attendu).
// Pour la vue basiqueClaude Leloup2012-03-01T17:08:06Sauf si c'est un terme de syntaxe, le nom de la vue peut Être omis :
long size = (Long) Files.getAttribute(path, size); // basic:size
FileTime time = (FileTime) Files.getAttribute(path, "creationTime"); // "basic:creationTime"
boolean isReadOnly = (Boolean) Files.getAttribute(path, "dos:readonly");
Files.setAttribute(path, "dos:readonly", false);
UserPrincipal owner = (UserPrincipal) Files.getAttribute(path, "user:owner");
...Il est ÃĐgalement possible de lire plusieurs attributs de cette maniÃĻre via la mÃĐthode Files.readAttributes(), qui utilise une notation similaire en permettant de rÃĐcupÃĐrer plusieurs attributs de la mÊme vue (en les sÃĐparant par des virgules). Le rÃĐsultat nous est alors retournÃĐ sous forme de Map<String,Object> :
Map<String,Object> map = Files.readAttributes(path, "dos:size,creationTime,readonly");
System.out.println(map);Il est mÊme possible d'utiliser le mÃĐtacaractÃĻre * pour rÃĐcupÃĐrer tous les attributs d'une vue, par exemple :
Map<String,Object> attributes = Files.readAttributes(path, "dos:*");
System.out.println(attributes);De ce fait, et grÃĒce à la mÃĐthode supportedFileAttributeViews() du FileSystem, il devient trÃĻs facile d'afficher tous les attributs d'un fichier :
Path path = Paths.get("file.txt");
FileStore fs = Files.getFileStore(path);
for (String viewName : path.getFileSystem().supportedFileAttributeViews()) {
if (fs.supportsFileAttributeView(viewName)) {
for (Map.Entry<String, Object> attr : Files.readAttributes(path, viewName+":*").entrySet()) {
System.out.println(viewName+":"+attr.getKey() + " = " + attr.getValue());
}
}
}WatchService : dÃĐtecter les changements dans un rÃĐpertoire▲
Il est dÃĐsormais possible de surveiller les modifications effectuÃĐes sur le contenu d'un rÃĐpertoire, afin d'Être averti (au choix) des crÃĐations/suppressions/modifications de fichiers via un WatchService, le tout en tirant avantage du systÃĻme de notification de fichier du systÃĻme d'exploitation hÃīte.
Si le systÃĻme d'exploitation ne dispose pas de mÃĐcanisme de surveillance de fichier, ceci sera ÃĐmulÃĐ en scannant rÃĐguliÃĻrement le rÃĐpertoire en question.
En enregistrant des rÃĐpertoires auprÃĻs du WatchService, on pourra obtenir des objets WatchKey regroupant une sÃĐrie d'ÃĐvÃĻnements sur un de ces rÃĐpertoires. On utilisera gÃĐnÃĐralement un thread sÃĐparÃĐ pour gÃĐrer tout cela.
Path path = ...
// On crÃĐe un objet WatchService, chargÃĐ de surveiller le dossier :
try (WatchService watcher = path.getFileSystem().newWatchService()) {
// On y enregistre un rÃĐpertoire, en lui associant certains types d'ÃĐvÃĻnements :
path.register(watcher,
StandardWatchEventKinds.ENTRY_CREATE,
StandardWatchEventKinds.ENTRY_DELETE,
StandardWatchEventKinds.ENTRY_MODIFY);
// (ou plusieurs)
// ...
// Puis on boucle pour rÃĐcupÃĐrer tous les ÃĐvÃĐnements :
while (true) {
// On rÃĐcupÃĻre une clef sur un ÃĐvÃĐnement (code bloquant)
WatchKey watchKey = watcher.take();
// On parcourt tous les ÃĐvÃĻnements associÃĐs à cette clef :
for (WatchEvent<?> event: watchKey.pollEvents()) {
if (event.king()==StandardWatchEventKinds.OVERFLOW)
continue; // ÃĐvÃĻnement perdu
System.out.println(event.kind() + " - " + event.context());
}
// On rÃĐinitialise la clef (trÃĻs important pour recevoir les ÃĐvÃĐnements suivants)
if ( watchKey.reset() ==false ) {
// Le rÃĐpertoire qu'on surveille n'existe plus ou n'est plus accessible
break;
}
}
}Attention : la liste des ÃĐvÃĻnements peut Être polluÃĐe par des ÃĐvÃĻnements perdus ou rejetÃĐs de type OVERFLOW (mÊme si on n'a pas enregistrÃĐ ce type d'ÃĐvÃĻnement). Il est donc impÃĐratif de les ignorer dans le code de traitement.
De mÊme, l'ordre et la quantitÃĐ d'ÃĐvÃĻnements gÃĐnÃĐrÃĐs dÃĐpendent fortement du systÃĻme d'exploitation hÃīte...
Dans l'implÃĐmentation actuelle, le WatchService ne permet que de surveiller les modifications apportÃĐes à un rÃĐpertoire. Il est impossible de surveiller uniquement un fichier, ni toute une arborescence (à moins de le faire manuellement bien sÃŧr), du fait des diffÃĐrences importantes entre les divers systÃĻmes de notification des systÃĻmes d'exploitation.
Toutefois, sous Windows, l'implÃĐmentation d'Oracle dispose d'un modificateur non standard qui permet cela : com.sun.nio.file.ExtendedWatchEventModifier.FILE_TREE. Il suffit de le passer à la mÃĐthode register() pour que toute l'arborescence soit surveillÃĐe automatiquement :
Path path = ...
path.register(ws, new WatchEvent.Kind<?>[]{
StandardWatchEventKinds.ENTRY_CREATE,
StandardWatchEventKinds.ENTRY_DELETE,
StandardWatchEventKinds.ENTRY_MODIFY},
com.sun.nio.file.ExtendedWatchEventModifier.FILE_TREE);
...Attention : ce modificateur FILE_TREE n'est pas standard et correspond à un ÃĐlÃĐment propriÃĐtaire de l'implÃĐmentation de la JVM d'Oracle, qui pourrait trÃĻs bien Être supprimÃĐe dans une version future. Il est donc prÃĐfÃĐrable de ne pas l'utiliser, et de privilÃĐgier des bibliothÃĻques tierces proposant cette fonctionnalitÃĐ (comme JNA/platform.jarJNA/platform.jar ou JNotifyJNotify).
ZIP FileSystem : gÃĐrer les archives Jar/Zip simplement !▲
Si la classe java.io.File reprÃĐsente uniquement un fichier sur le systÃĻme de fichiers de l'OS, la nouvelle API ne se limite pas à cela : un Path reprÃĐsente un chemin sur un systÃĻme de fichiers quelconque. Bien sÃŧr dans la majeure partie des cas ce sera sur le systÃĻme de fichiers de l'OS, mais en thÃĐorie cela pourrait Être sur n'importe quel systÃĻme de fichiers, rÃĐel ou logique...
En effet, l'API propose mÊme un mÃĐcanisme de provider permettant d'utiliser de nouvelle implÃĐmentation de systÃĻme de fichiers quelconque. Et afin de dÃĐmontrer cela, l'API de base propose un systÃĻme de fichiers ZIP permettant de traiter une archive jar/zip comme un systÃĻme de fichiers, de maniÃĻre totalement transparente.
// Via une rÃĐfÃĐrence de Path :
Path path = Paths.get("file.zip");
try ( FileSystem zipFS = FileSystems.newFileSystem(path, null) ) {
...
}
// Via une URI :
URI uri = URI.create("jar:file:/path/file.zip");
try ( FileSystem zipFS = FileSystems.newFileSystem(uri, null) ) {
...
}On peut alors utiliser la mÃĐthode getPath() du FileSystem pour obtenir un objet Path reprÃĐsentant un fichier à l'intÃĐrieur de l'archive, que l'on peut manipuler comme un fichier standard. De ce fait la manipulation des archives devient toute simple...
// CrÃĐation d'un systÃĻme de fichiers selon le contenu d'un fichier ZIP
try (FileSystem zipFS = FileSystems.newFileSystem(Paths.get("file.zip"), null)) {
// Suppression d'un fichier à l'intÃĐrieur du ZIP :
Files.deleteIfExists( zipFS.getPath("file.txt") );
// CrÃĐation d'un fichier à l'intÃĐrieur du ZIP :
Path path = zipFS.getPath("hello.txt");
Files.write(path, "Hello World !!!".getBytes());
// Parcours des ÃĐlÃĐments à l'intÃĐrieur du ZIP :
try (DirectoryStream<Path> stream = Files.newDirectoryStream(zipFS.getPath(/))) {
for (Path entry : stream) {
System.out.println(entry);
}
}
// Copie d'un fichier du disque vers l'archive ZIP :
Files.copy(Paths.get("on-disk.txt"), zipFS.getPath("on-zip.txt"));
}De la mÊme maniÃĻre, on pourrait imaginer toutes sortes d'implÃĐmentations de FileSystem, basÃĐes sur une zone mÃĐmoire, un FTP distant, un WebService, etc.
Autre exemple un peu plus complet : la dÃĐcompression complÃĻte d'une archive ZIP dans un rÃĐpertoire de destination. On utilise pour cela la mÃĐthode Fils.walkFileTree() afin de parcourir tous les ÃĐlÃĐments de l'archive :
public static void unzip(Path zipFile, final Path destDir)
throws IOException {
// On crÃĐe un FileSystem associÃĐ Ã l'archive :
try ( FileSystem zfs = FileSystems.newFileSystem(zipFile, null) ) {
// On parcourt tous les ÃĐlÃĐments root :
for (Path root : zfs.getRootDirectories()) {
// Et on parcourt toutes leurs arborescences :
Files.walkFileTree(root, new SimpleFileVisitor<Path>() {
private Path unzippedPath(Path path) {
return destDir.resolve("./" + path.toString());
}
@Override
public FileVisitResult preVisitDirectory(Path dir,
BasicFileAttributes attrs) throws IOException {
// On crÃĐe chaque rÃĐpertoire intermÃĐdiaire :
Files.createDirectories(unzippedPath(dir));
return FileVisitResult.CONTINUE;
}
@Override
public FileVisitResult visitFile(Path file,
BasicFileAttributes attrs) throws IOException {
// Et on copie chaque fichier :
Files.copy(file, unzippedPath(file),
StandardCopyOption.COPY_ATTRIBUTES,
StandardCopyOption.REPLACE_EXISTING);
return FileVisitResult.CONTINUE;
}
});
}
}
}JSR 203 - NIO.2 : entrÃĐes/sorties asynchrones▲
Le package java.nio.channels s'enrichit d'entrÃĐes/sorties asynchrones via les AsynchronousChannel, dont on dispose de trois implÃĐmentations :
- AsynchronousFileChannel;
- AsynchronousSocketChannel;
- AsynchronousServerSocketChannel.
Les AsynchronousChannel effectuent leurs opÃĐrations en tÃĒche de fond, afin de ne pas bloquer le code appelant. Chaque opÃĐration se prÃĐsente sous deux formes distinctes, permettant de rÃĐcupÃĐrer le rÃĐsultat de maniÃĻre active (via un appel explicite) ou passive (via une sorte de listener).
- Future<V> operation(args)
- void operation(args, A attachment, CompletionHandler<V,? super A> handler)
Future<V> operation(args)▲
Contrairement aux autres channels ou flux standards, et puisque les traitements sont asynchrones, les opÃĐrations des AsynchronousChannel rendent la main immÃĐdiatement. L'instance de Future<V> ainsi retournÃĐe permettra donc de surveiller ou arrÊter le traitement en tÃĒche de fond, mais surtout de rÃĐcupÃĐrer sa valeur de retour.
byte[] data = ...
Path path = Paths.get(...);
// On ouvre un AsynchronousFileChannel (dans un try-with-ressource)
try (AsynchronousFileChannel file = AsynchronousFileChannel.open(path,
StandardOpenOption.WRITE, StandardOpenOption.CREATE)) {
// On lance une opÃĐration d'ÃĐcriture en tÃĒche de fond
Future<Integer> task = file.write(ByteBuffer.wrap(data), 0);
// On effectue d'autres traitements
...
...
// On attend la fin de l'opÃĐration, et on rÃĐcupÃĻre son code de retour :
Integer result = task.get();
System.out.println( "byte writed : " + result);
}Afin de s'assurer du bon dÃĐroulement de l'opÃĐration, il est donc impÃĐratif d'utiliser la mÃĐthode get() de l'AsynchronousChannel.
void operation(args, A attachment, CompletionHandler<V,? super A> handler)▲
L'utilisation d'un CompletionHandler permet une approche diffÃĐrente. Au lieu de surveiller explicitement le rÃĐsultat de la mÃĐthode via un Future, il met en place un mÃĐcanisme proche des listeners. En clair, une fois que le traitement de l'opÃĐration se sera terminÃĐ correctement, la mÃĐthode completed() du CompletionHandler sera exÃĐcutÃĐe avec le rÃĐsultat en paramÃĻtre. En cas d'exception, ce sera la mÃĐthode failed() qui sera exÃĐcutÃĐe avec l'exception en question.
AsynchronousServerSocketChannel server =
AsynchronousServerSocketChannel.open();
server.bind(null);
server.accept(null, new CompletionHandler<AsynchronousSocketChannel, Void>() {
@Override
public void completed(AsynchronousSocketChannel client,
Void attachment) {
// Nouvelle connexion sur le server :
...
}
@Override
public void failed(Throwable exception, Void attachment) {
// Erreur de connexion :
exception.printStackTrace();
}
});L'objet CompletionHandler<V,A> est paramÃĐtrÃĐ avec deux types V et A. Le premier correspond à la valeur de retour de l'opÃĐration. Le second est totalement libre et correspond à un objet quelconque que l'on pourra associer à l'opÃĐration (par exemple un identifiant).
JSR 166 - API de concurrence▲
Ces derniÃĻres annÃĐes, les architectures multiprocesseurs ou multicores se sont gÃĐnÃĐralisÃĐes. Depuis Java 5, la plateforme Java s'est adaptÃĐe à cette mouvance via l'API java.util.concurrent qui fournit un ensemble de fonctionnalitÃĐs facilitant l'utilisation de tout cela.
La cuvÃĐe Java 7 nous apporte la notion de TransferQueue (implÃĐmentÃĐe via LinkedTransferQueue), qui permet de passer des ÃĐlÃĐments d'un producteur à un consommateur de maniÃĻre bloquante. Mais à la diffÃĐrence de BlockingQueue dont elle hÃĐrite, cette interface permet, via la mÃĐthode transfer(), de bloquer le producteur tant qu'aucun consommateur ne vient rÃĐcupÃĐrer les donnÃĐes.
On notera ÃĐgalement la classe ThreadLocalRandom, qui permet d'obtenir une instance unique par thread, afin d'ÃĐviter toutes dÃĐgradations de la qualitÃĐ des nombres alÃĐatoires. En effet la classe Random n'est pas thread-safe, et son utilisation en parallÃĻle peut poser plusieurs problÃĻmes.
Mais la principale nouveautÃĐ de cette version vient du framework Fork/Join.
Fork/Join - diviser pour mieux rÃĐgner▲
Le gros apport de Java 7 vient du framework Fork/Join, qui consiste à dÃĐcouper une grosse tÃĒche en plusieurs tÃĒches plus petites, afin de les exÃĐcuter via diffÃĐrents threads, et ainsi profiter de toutes la puissance de calcul disponible. Le principe est simple : si un gros problÃĻme peut Être dÃĐcoupÃĐ en plusieurs petits problÃĻmes, on peut alors les rÃĐpartir sur plusieurs processeurs afin d'amÃĐliorer le traitement global.
Prenons un exemple tout bÊte mais consommateur de temps CPU : on va calculer la somme des cosinus et sinus de toutes les valeurs entiÃĻres comprises entre 0 et une valeur 'n', via la formule suivante :
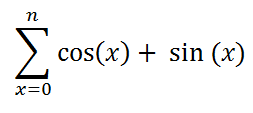
Basiquement on implÃĐmenterait ceci via une simple boucle :
public static double calculate(int max) {
double result = 0.0;
for (int i=0; i<max; i++)
result += Math.cos(i) + Math.sin(i);
return result;
}Ce genre de calcul requiert du temps CPU, surtout en cas de valeurs assez importantes. à titre d'exemple, l'appel de calculate(10_000_000) prend en moyenne un peu plus de 10 secondes sur ma machine de test, dotÃĐ d'un processeur quadricore. Mais cette boucle n'utilise en tout et pour tout qu'un seul et unique CPU. On va donc utiliser le framework Fork/Join afin de bien mettre à profit tout ce petit monde en parallÃĐlisant le travail. Chaque ÃĐtape de la boucle ÃĐtant parfaitement indÃĐpendante et ne nÃĐcessitant pas un ordre prÃĐcis d'exÃĐcution. On peut donc parfaitement dÃĐcouper cette tÃĒche en plusieurs sous-tÃĒches plus petites. Le principe consiste à dÃĐcouper la tÃĒche en sous-tÃĒches plus petites jusqu'à qu'elles soient suffisamment simples à exÃĐcuter. à partir de là les diffÃĐrentes tÃĒches pourront Être exÃĐcutÃĐes en parallÃĻle via diffÃĐrents threads.
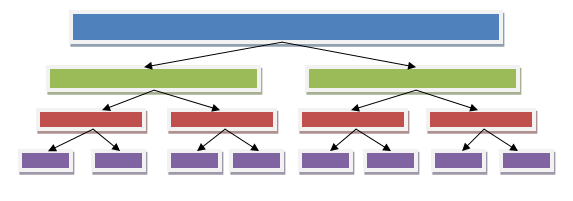
La premiÃĻre ÃĐtape consiste à dÃĐterminer un seuil au-dessus duquel on va dÃĐcouper la tÃĒche. Ici on va prendre arbitrairement la valeur 10_000, qui peut Être calculÃĐe dans un temps correct. Il faut ensuite crÃĐer une tÃĒche ÃĐtendant la classe RecursiveTask<T>, qui se chargera d'implÃĐmenter notre traitement. C'est un peu plus long, mais il n'y a rien d'insurmontable :
class CalculateTask extends RecursiveTask<Double> {
private static final int MAX_VALUES = 10_000;
private final int start;
private final int stop;
/**
* Constructeur
*/
private CalculateTask(int start, int stop) {
this.start = start;
this.stop = stop;
}
/**
* MÃĐthode interne de calcul entre deux index.
*/
private static double calculate(int start, int stop) {
double result = 0.0;
for (int i=start; i<stop; i++)
result += Math.cos(i) + Math.sin(i);
return result;
}
/**
* Traitement de la tÃĒche
*/
@Override
protected Double compute() {
final int count = this.stop - this.start;
// S'il y a peu d'ÃĐlÃĐments à calculer :
if (count<MAX_VALUES) {
// On effectue le calcul et on renvoie le rÃĐsultat :
return calculate(this.start, this.stop);
}
// Sinon on coupe la tÃĒche en deux :
final int middle = count/2;
// On crÃĐe une premiÃĻre tÃĒche qu'on va exÃĐcuter en arriÃĻre-plan (via fork()) :
CalculateTask task1 = new CalculateTask(this.start, this.start+middle);
task1.fork();
// On crÃĐe une seconde tÃĒche qu'on va exÃĐcuter directement (via compute()),
// ce qui nous permet de rÃĐcupÃĐrer son rÃĐsultat :
CalculateTask task2 = new CalculateTask(this.start+middle, this.stop);
double value2 = task2.compute();
// On attend la fin de la premiÃĻre tÃĒche pour rÃĐcupÃĐrer son rÃĐsultat :
double value1 = task1.join();
// Et on retourne
return value1 + value2;
}
/**
* ExÃĐcution de la tÃĒche via un ForkJoinPool.
*/
public static double calculate(int max) {
ForkJoinPool pool = new ForkJoinPool();
return pool.invoke(new CalculateTask(0, max));
}
}La principale difficultÃĐ vient de la mÃĐthode fork(). En utilisant cette mÃĐthode sur une sous-tÃĒche, on l'envoie dans le pool de traitement, afin qu'elle soit exÃĐcutÃĐe dans un autre thread. On peut alors exÃĐcuter directement le code d'une sous-tÃĒche, puis rÃĐcupÃĐrer le rÃĐsultat via la mÃĐthode join().
La mÃĐthode static calculate(int) permet d'exÃĐcuter la tÃĒche dans un ForkJoinPool. Ce dernier sera chargÃĐ de rÃĐpartir les tÃĒches sur plusieurs threads, afin qu'ils s'exÃĐcutent sur les diffÃĐrents processeurs de la machine.
/**
* ExÃĐcution de la tÃĒche via un ForkJoinPool.
*/
public static double calculate(int max) {
ForkJoinPool pool = new ForkJoinPool();
return pool.invoke(new CalculateTask(0, max));
}Sur la mÊme machine, le calcul est alors effectuÃĐ en moyenne entre 2.5 et 3 secondes, ce qui est approximativement quatre fois plus rapide (normal puisqu'il s'agit d'un quadricore).
Par dÃĐfaut le ForkJoinPool crÃĐera autant de threads qu'il y a de processeurs disponibles sur la machine hÃīte. Mais il est bien sÃŧr possible de contrÃīler cela via son constructeur (entre autres).
Attention : la multiplication des tÃĒches n'engendre pas forcÃĐment un meilleur rÃĐsultat. Car si l'exÃĐcution en parallÃĻle permet bien de profiter de toute la puissance de calcul, cela ajoute ÃĐgalement une synchronisation des donnÃĐes qui pourrait nuire au temps de traitement. Des tÃĒches trop petites ou trop nombreuses pourraient Être contre-productives...
Dans le mÊme ordre d'idÃĐe, on peut se passer totalement du ForkJoinPool si le problÃĻme est simple ou qu'on ne dispose pas de suffisamment de processeurs :
/**
* ExÃĐcution de la tÃĒche via un ForkJoinPool.
*/
public static double calculate(int max) {
// Si le problÃĻme est complexe, et qu'on dispose de plusieurs processeurs :
if (max>MAX_VALUES && Runtime.getRuntime().availableProcessors()>1) {
// On exÃĐcute le traitement via un ForkJoinPool :
ForkJoinPool pool = new ForkJoinPool();
return pool.invoke(new CalculateTask(0, max));
} else {
// Sinon on effectue le calcul directement :
return calculate(0, max);
}
}Phaser▲
La classe Phaser permet un nouveau mode de synchronisation de tÃĒches, qui permet de mettre en phase plusieurs parties distinctes.
Les "parties" correspondent aux diffÃĐrentes tÃĒches en exÃĐcution. Chaque partie doit s'inscrire auprÃĻs du Phaser, puis indiquer son ÃĐtat d'avancement au fur et à mesure. Lorsque toutes les parties sont arrivÃĐes à terme, la phase courante s'incrÃĐmente et chaque tÃĒche continue ses traitements jusqu'à la prochaine phase...
Prenons un exemple tout simple : on souhaite dÃĐmarrer cinq threads contenant chacun trois ÃĐtapes distinctes.
for (int i = 0; i < 5; i++) {
new Thread() {
public void run() {
System.out.println("Ãtape 1 : " + getName());
System.out.println("Ãtape 2 : " + getName());
System.out.println("Ãtape 3 : " + getName());
}
}.start();
}Ici nous n'avons aucun contrÃīle sur l'ordre d'exÃĐcution. Le thread 1 peut trÃĻs bien finir toutes ses ÃĐtapes avant mÊme que le thread 2 n'ait dÃĐbutÃĐ sa premiÃĻre ÃĐtape, ou inversement.
Si l'ordre d'exÃĐcution est toujours le mÊme au sein d'un mÊme thread, le rÃĐsultat global pourra beaucoup varier d'une exÃĐcution à l'autre, avec des ÃĐtapes 1, 2 et 3 totalement "mÃĐlangÃĐes" :
Ãtape 1 : Thread-0
Ãtape 2 : Thread-0
Ãtape 3 : Thread-0
Ãtape 1 : Thread-2
Ãtape 1 : Thread-4
Ãtape 2 : Thread-4
Ãtape 3 : Thread-4
Ãtape 1 : Thread-1
Ãtape 1 : Thread-3
Ãtape 2 : Thread-3
Ãtape 3 : Thread-3
Ãtape 2 : Thread-1
Ãtape 2 : Thread-2
Ãtape 3 : Thread-1
Ãtape 3 : Thread-2On souhaite dÃĐsormais que chaque thread soit synchronisÃĐ aux autres, afin qu'il ne passe à l'ÃĐtape suivante qu'à partir du moment oÃđ tous les autres threads ont terminÃĐ l'ÃĐtape courante. C'est-à -dire que l'ÃĐtape 2 ne dÃĐbute que lorsque tous les threads ont terminÃĐ la premiÃĻre ÃĐtape, etc.
Le Phaser nous permet de faire cela assez simplement, en enregistrant chaque tÃĒche au Phaser. Ce dernier utilise tout simplement un compteur permettant de dÃĐterminer le nombre de tÃĒches terminÃĐes. Chaque thread doit alors utiliser la mÃĐthode arriveAndAwaitAdvance() pour indiquer qu'il a terminÃĐ une tÃĒche et qu'il attend le dÃĐbut de la tÃĒche suivante :
final Phaser phaser = new Phaser();
for (int i = 0; i < 5; i++) {
// On enregistre un nouveau thread dans le phaser :
phaser.register();
new Thread() {
public void run() {
System.out.println("Ãtape 1 : " + getName());
phaser.arriveAndAwaitAdvance();
System.out.println("Ãtape 2 : " + getName());
phaser.arriveAndAwaitAdvance();
System.out.println("Ãtape 3 : " + getName());
phaser.arriveAndDeregister();
}
}.start();
}MÊme si l'ordonnancement des threads entre eux n'est toujours pas prÃĐvisible, on peut garantir l'ordonnancement des ÃĐtapes de chaque thread :
Ãtape 1 : Thread-1
Ãtape 1 : Thread-3
Ãtape 1 : Thread-2
Ãtape 1 : Thread-0
Ãtape 1 : Thread-4
Ãtape 2 : Thread-4
Ãtape 2 : Thread-1
Ãtape 2 : Thread-0
Ãtape 2 : Thread-3
Ãtape 2 : Thread-2
Ãtape 3 : Thread-1
Ãtape 3 : Thread-0
Ãtape 3 : Thread-3
Ãtape 3 : Thread-2
Ãtape 3 : Thread-4La Phaser permet d'appliquer plusieurs types de synchronisation des phases. N'hÃĐsitez pas à consulter sa documentation pour d'autres exemples.
AWT/Swing▲
La classe TransferHandler se voit dotÃĐe d'une mÃĐthode setDragImage() permettant de dÃĐfinir une image à afficher pendant le drag&drop.
Les classes JList et JComboBox utilisent dÃĐsormais les Generics pour paramÃĐtrer le type de leurs donnÃĐes : JList<E> et JComboBox<E>.
Il est dÃĐsormais possible d'associer un type à une fenÊtre, via la mÃĐthode setType() et l'ÃĐnumÃĐration Window.Type contenant trois valeurs possibles : NORMAL pour le comportement par dÃĐfaut, POPUP pour les fenÊtres temporaires et UTILITY pour les barres d'outils ou palettes. Selon le systÃĻme d'exploitation hÃīte, les caractÃĐristiques de ces fenÊtres peuvent varier.
La classe BorderFactory s'enrichit de nouveaux types de bordures, via les mÃĐthodes createDashedBorder(), createLineBorder(), createLoweredSoftBevelBorder(), createRaisedSoftBevelBorder(), createSoftBevelBorder() et createStrokeBorder().
FenÊtres transparentes et non rectangulaires▲
Java 6 avait reçu une grosse mise à jour via son update 10, qui a apportÃĐ plusieurs nouvelles fonctions et amÃĐliorations, ainsi que de nouvelles API internes normalement rÃĐservÃĐes à Sun/Oracle. Ces API ont ÃĐtÃĐ standardisÃĐes avec la sortie de Java 7.
TRANSLUCENT - transparence globale▲
Nous disposons dÃĐsormais d'une mÃĐthode setOpacity() permettant de dÃĐfinir le niveau d'opacitÃĐ globale de la fenÊtre, en utilisant des valeurs comprises entre 0.0 (la fenÊtre est invisible) et 1.0 (la fenÊtre est totalement opaque).
JLabel label = new JLabel("Hello World !");
label.setForeground(Color.WHITE);
label.setFont(label.getFont().deriveFont(48.F));
label.setBorder(BorderFactory.createEmptyBorder(32, 32, 32, 32));
final JFrame frame = new JFrame();
frame.setUndecorated(true);
frame.add(label);
frame.pack();
frame.setLocationRelativeTo(null);
frame.addMouseListener(new MouseAdapter() {
@Override
public void mouseClicked(MouseEvent e) {
frame.dispose();
}
});
//
// On applique à la fenÊtre une transparence globale à 75 %
//
frame.setOpacity(0.75F);
frame.getContentPane().setBackground(Color.BLACK);
frame.setVisible(true);Ce qui nous donnera comme rÃĐsultat quelque chose comme ceci :

PERPIXEL_TRANSLUCENT - transparence pixel par pixel▲
Contrairement à la transparence globale, la transparence pixel par pixel nous permet de dÃĐfinir le niveau de transparence de chaque pixel de la fenÊtre. Pour activer la transparence pixel par pixel, il faut appliquer une couleur de fond transparente à la fenÊtre en utilisant la mÃĐthode setBackground() avec une couleur contenant une composante alpha correspond à son niveau de transparence :
JLabel label = new JLabel("Hello World !");
label.setForeground(Color.WHITE);
label.setFont(label.getFont().deriveFont(48.F));
label.setBorder(BorderFactory.createEmptyBorder(32, 32, 32, 32));
final JFrame frame = new JFrame();
frame.setUndecorated(true);
frame.add(label);
frame.pack();
frame.setLocationRelativeTo(null);
frame.addMouseListener(new MouseAdapter() {
@Override
public void mouseClicked(MouseEvent e) {
frame.dispose();
}
});
//
// On applique à la fenÊtre un fond noir transparent à 75 %
//
frame.setBackground(new Color(0F,0F,0F,0.75F));
frame.setVisible(true);Le rÃĐsultat peut sembler identique, mais on remarquera ici que le texte de la fenÊtre est complÃĻtement opaque, car on ne lui a pas affectÃĐ de niveau de transparence :
On peut mÊme imaginer des rendus plus complexes en spÃĐcifiant une couleur de fond totalement transparente, et en laissant les composants spÃĐcifier leur propre niveau de transparence, ou mÊme en utilisant Java2D pour dessiner la fenÊtre :
JLabel label = new JLabel("Hello World !");
label.setForeground(Color.WHITE);
label.setFont(label.getFont().deriveFont(48.F));
label.setBorder(BorderFactory.createEmptyBorder(32, 32, 32, 32));
final JFrame frame = new JFrame();
// On utilise un ContentPane avec un fond en dÃĐgradÃĐ :
frame.setContentPane(new JPanel() {
@Override
protected void paintComponent(Graphics g) {
Graphics2D g2d = (Graphics2D)g;
g2d.setRenderingHint(RenderingHints.KEY_ANTIALIASING,RenderingHints.VALUE_ANTIALIAS_ON);
int w = getWidth();
int h = getHeight();
// dÃĐgradÃĐ allant de noir invisible à noir opaque :
g2d.setPaint(new GradientPaint(
0,0,new Color(0,0,0,0),
w,h,new Color(0,0,0,255), true));
g2d.fillRect(0, 0, w, h);
}
});
frame.setUndecorated(true);
frame.add(label);
frame.pack();
frame.setLocationRelativeTo(null);
frame.addMouseListener(new MouseAdapter() {
@Override
public void mouseClicked(MouseEvent e) {
frame.dispose();
}
});
//
// On applique à la fenÊtre un fond complÃĻtement transparent
//
frame.setBackground(new Color(0F,0F,0F,0F));
frame.setVisible(true);PERPIXEL_TRANSPARENT - forme non rectangulaire▲
Il est dÃĐsormais possible de crÃĐer des fenÊtres non rectangulaires, en dÃĐfinissant un masque qui dÃĐterminera la visibilitÃĐ des pixels. On utilisera pour cela la mÃĐthode setShape() avec la forme dÃĐsirÃĐe :
JLabel label = new JLabel("Hello World !");
label.setForeground(Color.WHITE);
label.setFont(label.getFont().deriveFont(48.F));
label.setBorder(BorderFactory.createEmptyBorder(32, 32, 32, 32));
final JFrame frame = new JFrame();
frame.setUndecorated(true);
frame.add(label);
frame.pack();
frame.setLocationRelativeTo(null);
frame.addMouseListener(new MouseAdapter() {
@Override
public void mouseClicked(MouseEvent e) {
frame.dispose();
}
});
frame.getContentPane().setBackground(Color.BLACK);
//
// On applique un masque sur la fenÊtre
//
frame.setShape(new RoundRectangle2D.Double(0,0,frame.getWidth(),frame.getHeight(),64,64));
frame.setVisible(true);Ce qui nous donnera comme rÃĐsultat quelque chose comme ceci :

Contrairement aux modes prÃĐcÃĐdents, il est garanti que les pixels cachÃĐs via la mÃĐthode setShape() ne soient pas cliquables. Bref c'est exactement comme s'ils n'existaient pas du tout.
CompatibilitÃĐ et support▲
Toutes ces fonctionnalitÃĐs nÃĐcessitent un support spÃĐcifique sur le systÃĻme hÃīte, et ne seront pas forcÃĐment toujours disponibles. Il faut impÃĐrativement rÃĐcupÃĐrer le GraphicsDevice associÃĐ Ã la fenÊtre afin de vÃĐrifier s'il supporte ces fonctionnalitÃĐs via la mÃĐthode isWindowTranslucencySupported() :
| isWindowTranslucencySupported() | FonctionnalitÃĐ supportÃĐe | MÃĐthode |
|---|---|---|
| WindowTranslucency.TRANSLUCENT | Transparence globale | setOpacity() |
| WindowTranslucency.PERPIXEL_TRANSLUCENT et GraphicsConfiguration().isTranslucencyCapable() |
Transparence pixel par pixel | setBackground() (avec une composante alpha) |
| WindowTranslucency.PERPIXEL_TRANSPARENT | Forme non rectangulaire | setShape() |
La transparence pixel par pixel nÃĐcessite ÃĐgalement un support au niveau de la configuration graphique, ce que l'on peut vÃĐrifier via la mÃĐthode isTranslucencyCapable() du GraphicsConfiguration :
GraphicsDevice device = frame.getGraphicsConfiguration().getDevice();
if (device.isWindowTranslucencySupported(WindowTranslucency.TRANSLUCENT)) {
System.out.println("La transparence globale est supportÃĐe !");
}
if (device.isWindowTranslucencySupported(WindowTranslucency.PERPIXEL_TRANSLUCENT)
&& frame.getGraphicsConfiguration().isTranslucencyCapable()) {
System.out.println("La transparence pixel par pixel est supportÃĐe !");
}
if (device.isWindowTranslucencySupported(WindowTranslucency.PERPIXEL_TRANSPARENT)) {
System.out.println("Les formes non rectangulaires sont supportÃĐes !");
}Ces fonctionnalitÃĐs sont intÃĐgrÃĐes dans la classe java.awt.Window, c'est-à -dire que l'on peut les utiliser sur tout type de fenÊtre AWT (Window, Dialog, Frame) ou Swing (JWindow, JDialog, JFrame), à condition de respecter quelques conditions :
- la fenÊtre ne doit pas comporter de dÃĐcoration systÃĻme (ce que l'on peut forcer via setUndecorated(true)) ;
- la fenÊtre ne doit pas utiliser le mode d'affichage en plein ÃĐcran exclusif.
Secondary Loop▲
Swing est monotÃĒche. C'est-à -dire que toutes les modifications des composants graphiques doivent Être effectuÃĐes dans un seul et unique thread : l'EDT (Event Dispatch Thread). Ce thread s'occupe d'exÃĐcuter tous les traitements relatifs à l'interface graphique (affichage des composants, gestion des ÃĐvÃĻnements, etc.). Pour cela il utilise en fait une boucle infinie qui va traiter toutes les tÃĒches les unes à la suite des autres. C'est pour cette raison que les traitements exÃĐcutÃĐs dans l'EDT ne doivent pas Être trop lents ou bloquants, car cela dÃĐcalerait l'exÃĐcution de toutes les autres tÃĒches.
On utilise donc gÃĐnÃĐralement un thread (via la classe SwingWorker par exemple) pour exÃĐcuter nos traitements lents afin de ne pas bloquer l'EDT (ce qui se caractÃĐrise par un gel de l'interface, voire des bogues graphiques). Pourtant il peut parfois Être utile de bloquer le traitement de l'EDT, par exemple pour attendre une rÃĐponse de l'utilisateur. C'est ce qui se produit lorsqu'on utilise une boite de dialogue modale.
DÃĐsormais, il est ÃĐgalement possible d'utiliser l'objet SecondaryLoop pour bloquer proprement l'EDT en crÃĐant une nouvelle boucle de traitement, qui s'occupera de traiter les tÃĒches pendant ce temps. Cela permet de bloquer la boucle principale de l'EDT, qui continuera malgrÃĐ tout ses traitements via une nouvelle boucle temporaire...
public static <V> V invokeNow(Callable<V> code) {
try {
if (!SwingUtilities.isEventDispatchThread()) {
// On n'est pas dans l'EDT, on peut
// appeler le code directement :
return code.call();
}
// On rÃĐcupÃĻre l'EventQueue pour crÃĐer la SecondaryLoop :
EventQueue eventQueue = Toolkit.getDefaultToolkit().getSystemEventQueue();
final SecondaryLoop secondaryLoop = eventQueue.createSecondaryLoop();
// On crÃĐe un FutureTask, qui exÃĐcutera notre code
// et stoppera la SecondaryLoop à la fin du traitement :
FutureTask<V> future = new FutureTask<V>(code) {
protected void done() {
secondaryLoop.exit();
}
};
// On dÃĐmarre notre tÃĒche dans un thread :
new Thread(future).start();
// On rentre dans la SecondaryLoop, ce qui
// est bloquant tant que la mÃĐthode exit()
// n'est pas appelÃĐe...
secondaryLoop.enter();
// On retourne notre rÃĐsultat :
return future.get();
} catch (Exception e) {
throw new RuntimeException(e);
}
}En dehors de l'EDT, cette mÃĐthode exÃĐcutera simplement le code de l'objet Callable en paramÃĻtre.
Dans l'EDT, elle exÃĐcutera le code dans un thread sÃĐparÃĐ, en entrant dans la SecondaryLoop via enter(), afin que l'EDT puisse continuer son travail pendant ce temps. Cette nouvelle boucle ne prendra fin qu'aprÃĻs l'appel de exit()) Ã la fin de la tÃĒche de l'objet Callable.
JLayer<T> : un calque pour vos composants▲
Swing s'enrichit d'un nouveau composant hÃĐritÃĐ du projet SwingLabs : JLayer. Comme son nom l'indique, ce dernier se comporte comme une couche qui viendrait englober n'importe quel composant, afin de modifier son comportement ou son affichage.
JPanel panel = ...
JLayer<JPanel> layer = new JLayer<JPanel>(panel);Par dÃĐfaut le JLayer ne fait rien. Contrairement aux autres composants graphiques qui obtiennent leur UI du Look&Feel, il faut explicitement associer un LayerUI Ã chaque instance de JLayer. Cela permet de dÃĐfinir la maniÃĻre dont le JLayer sera dessinÃĐ, et donc indirectement de la maniÃĻre dont sera dessinÃĐ le composant qu'il contient.
Par exemple, via la mÃĐthode paint() du LayerUI, il est possible de modifier le rendu d'un composant.
JLayer<JPanel> layer = new JLayer<JPanel>(panel);
layer.setUI(new LayerUI<Component>() {
private final Color MASK = new Color(1.0f, 0f, 0f, 0.2f);
@Override
public void paint(Graphics g, JComponent c) {
// On dessine le composant normalement :
super.paint(g, c);
// Puis on dessine un carrÃĐ transparent par-dessus :
g.setColor(MASK);
Rectangle r = g.getClipBounds();
g.fillRect(r.x, r.y, r.width, r.height);
}
});
Il est ÃĐgalement possible d'interagir au niveau des ÃĐvÃĻnements. La classe JLayer permet d'activer certains ÃĐvÃĻnements via la mÃĐthode setLayerEventMask(). Cela permet ensuite de les recevoir (avant le composant) afin de les traiter, voire mÊme de les inhiber.
Par exemple, on pourrait utiliser cela pour dÃĐsactiver n'importe quel composant. La plupart des composants Swing permettent dÃĐjà cela via la mÃĐthode setEnabled(). Les JButton, JTextField ou autres contrÃīles seront bien grisÃĐs et inaccessibles. Mais on ne peut pas utiliser directement cela sur un JPanel par exemple : le composant sera bien dans l'ÃĐtat 'disabled', mais cela n'aura aucun impact sur les composants qu'il comporte.
Il est possible de simuler ce comportement avec un LayerUI adaptÃĐ, par exemple en dessinant une couche grise par-dessus le composant, et en inhibant tous ses ÃĐvÃĻnements clavier/souris :
public class DisabledLayerUI extends LayerUI<Component> {
private final Color MASK = new Color(0.2f, 0.2f, 0.2f, 0.2f);
/*
* Installation du LayerUI sur un JLayer.
* On active les ÃĐvÃĻnements souris et clavier.
*/
@Override
public void installUI(JComponent component) {
JLayer<?> layer = (JLayer<?>) component;
layer.setLayerEventMask(AWTEvent.MOUSE_EVENT_MASK
| AWTEvent.MOUSE_MOTION_EVENT_MASK
| AWTEvent.KEY_EVENT_MASK);
}
/*
* DÃĐsinstallation du LayerUI.
* On dÃĐsactive tous les ÃĐvÃĻnements.
*/
@Override
public void uninstallUI(JComponent c) {
JLayer<?> layer = (JLayer<?>) c;
layer.setLayerEventMask(0);
}
/*
* Dessin du composant.
* Si la vue est 'disabled', on dessine un masque gris par-dessus.
*/
public void paint(Graphics g, JComponent component) {
super.paint(g, component);
JLayer<?> layer = (JLayer<?>) component;
if (layer.getView().isEnabled() == false) {
g.setColor(MASK);
Rectangle r = g.getClipBounds();
g.fillRect(r.x, r.y, r.width, r.height);
}
}
/*
* Traitement des ÃĐvÃĻnements.
* Si la vue est 'disabled', on consomme tous les ÃĐvÃĻnements clavier/souris.
* Ainsi ils ne seront pas reçus par le composant.
*/
@Override
protected void processKeyEvent(KeyEvent event, JLayer<? extends Component> layer) {
if (layer.getView().isEnabled()==false) {
event.consume();
}
}
@Override
protected void processMouseEvent(MouseEvent event, JLayer<? extends Component> layer) {
if (layer.getView().isEnabled()==false) {
event.consume();
}
}
@Override
protected void processMouseMotionEvent(MouseEvent event, JLayer<? extends Component> layer) {
if (layer.getView().isEnabled()==false) {
event.consume();
}
}
}Le simple fait d'englober un JPanel dans un JLayer avec cet UI nous permettra donc de dÃĐsactiver tout le JPanel simplement, ce qui aura pour effet de bloquer tous les ÃĐvÃĻnements clavier/souris sur tous les composants qu'il comporte :
JLayer<JPanel> layer = new JLayer<JPanel>(panel);
layer.setUI(new DisabledUI()); |
 |
Nimbus, le nouveau LookAndFeel▲
Le Look&Feel Nimbus est ÃĐgalement prÃĐsent depuis l'update 10 de Java 6, de maniÃĻre propriÃĐtaire et spÃĐcifique à la JVM d'Oracle/Sun. Avec Java 7 il est enfin officialisÃĐ via la classe javax.swing.plaf.nimbus.NimbusLookAndFeel.
UIManager.setLookAndFeel("javax.swing.plaf.nimbus.NimbusLookAndFeel");Toutefois ce code n'est valide qu'avec Java 7. Si notre application cible ÃĐgalement Java 6, il est prÃĐfÃĐrable de rechercher la prÃĐsence de Nimbus via son nom, puisque le nom de la classe est diffÃĐrent :
for (LookAndFeelInfo info : UIManager.getInstalledLookAndFeels()) {
if ("Nimbus".equals(info.getName())) {
UIManager.setLookAndFeel(info.getClassName());
break;
}
}Nimbus apporte donc un nouveau Look&Feel, que chacun apprÃĐciera (ou pas) :
 |
 |
Comme la plupart des Look&Feels, les propriÃĐtÃĐs de l'UIManager restent au c?ur de la personnalisation du rendu des composants. Nimbus n'ÃĐchappe pas à la rÃĻgle et propose une tripotÃĐe de clefs permettant de modifier les couleurs, polices de caractÃĻres, marges et mÊme la maniÃĻre de dessiner les composants.
Bien entendu, pour des raisons de compatibilitÃĐ, le Look&Feel par dÃĐfaut restera Metal.
Les couleurs (primaires et secondaires)▲
Nimbus se base sur un jeu de 14 couleurs primaires, associÃĐes à une clef. Ces couleurs primaires permettent de gÃĐnÃĐrer 21 couleurs secondaires par dÃĐrivation. Il est bien sÃŧr possible de modifier chacune de ces couleurs indÃĐpendamment via l'UIManager, ce qui aura un impact direct sur tous les composants de l'interface graphique.
On peut retrouver la liste de ces couleurs et de leur valeur par dÃĐfaut à cette adresse :
http://download.oracle.com/javase/7/docs/api/javax/swing/plaf/nimbus/doc-files/properties.htmlPrimary & Secondary Colors.
On peut ÃĐgalement retrouver la liste des toutes les propriÃĐtÃĐs de l'UIManager qui sont dÃĐfinies par dÃĐfaut par le Look&Feel Nimbus à cette adresse :
http://download.oracle.com/javase/tutorial/uiswing/lookandfeel/_nimbusDefaults.htmlNimbus Defaults.
Par dÃĐfaut (lorsqu'on ne les dÃĐfinit pas), les couleurs secondaires sont automatiquement crÃĐÃĐes en dÃĐrivant les couleurs primaires. Il est ainsi possible de se contenter de redÃĐfinir les couleurs primaires pour modifier l'interface globale de maniÃĻre cohÃĐrente. Il est mÊme possible de ne modifier que certaines d'entre elles pour avoir un rÃĐsultat cohÃĐrent, puisque la modification d'une couleur primaire aura des impacts sur la valeur par dÃĐfaut des couleurs secondaires :
UIManager.put("nimbusBase", new ColorUIResource(51, 140, 98));
UIManager.setLookAndFeel("javax.swing.plaf.nimbus.NimbusLookAndFeel");| |
 |
Attention à bien redÃĐfinir les couleurs avant d'appliquer le Look&Feel Nimbus, sinon certaines couleurs pourraient ne pas Être prises en compte...
Les ÃĐtats (states)▲
Nimbus introduit la notion d'ÃĐtats au niveau des propriÃĐtÃĐs de l'UIManager, via sept ÃĐtats standards :
- Enabled ne s'applique que si le composant est activÃĐÂ ;
- Disabled ne s'applique que si le composant est dÃĐsactivÃĐÂ ;
- MouseOver ne s'applique que lorsque la souris survole le composant ;
- Focused ne s'applique que lorsque le composant possÃĻde le focus ;
- Selected ne s'applique que lorsque le composant est sÃĐlectionnÃĐÂ ;
- Pressed ne s'applique qu'à l'instant oÃđ l'on clique sur le composant ;
- Default s'applique au bouton par dÃĐfaut de la fenÊtre (dÃĐfini via JRootPane.setDefaultButton()).
Ces diffÃĐrents ÃĐtats sont utilisables avec les propriÃĐtÃĐs de l'UIManager, afin de modifier le rendu du composant de maniÃĻre conditionnelle. On utilise pour cela une notation entre crochets aprÃĻs le type du composant. Ainsi, si Button.textForeground permet de modifier la couleur du texte de tous les boutons, Button[MouseOver].textForeground permet d'effectuer cela uniquement lors du passage de la souris, tandis que Button[Focused].textForeground ne modifiera que le bouton possÃĐdant le focus...
Il est ainsi possible d'apporter un cÃītÃĐ dynamique en modifiant le rendu des ÃĐlÃĐments selon leur ÃĐtat, sans forcÃĐment avoir recours à un listener :
UIManager.put("Button[MouseOver].textForeground", Color.RED);Il est possible de prÃĐciser plusieurs ÃĐtats en mÊme temps, en les sÃĐparant par le signe + :
UIManager.put("Button[Default+MouseOver].textForeground", Color.RED);Attention, lorsqu'on dÃĐfinit une clef de base (sans ÃĐtat), elle prend le dessus sur toutes les autres clefs. Pour ÃĐviter ce comportement, il faut utiliser les UIResources (par exemple en utilisant new ColorUIResource(Color.BLACK) au lieu d'utiliser directement Color.BLACK).
à noter ÃĐgalement l'existence de la clef Composant.States permettant de redÃĐfinir les ÃĐtats à prendre en considÃĐration. Lorsqu'elle est utilisÃĐe, cette clef doit contenir la liste de tous les ÃĐtats supportÃĐs, sÃĐparÃĐs par des virgules.
// 'MouseOver' ne fait pas partie de cette liste d'ÃĐtats :
UIManager.put("Button.States", "Enabled,Disabled,Focused,Selected,Pressed,Default");Cette propriÃĐtÃĐ permet surtout de dÃĐfinir de nouveaux ÃĐtats plus spÃĐcifiques, en y incluant le nom des nouveaux ÃĐtats que l'on veut mettre en place. Puis, pour chaque nouvel ÃĐtat, il faut dÃĐfinir une propriÃĐtÃĐ Composant.Etat pointer vers une instance de la classe javax.swing.plaf.nimbus.State qui permettra au Look&Feel de dÃĐterminer si le composant appartient à un ÃĐtat ou pas via la mÃĐthode isInState().
Par exemple, pour rajouter un ÃĐtat Empty aux JTextField, on utiliserait le code suivant :
// 1. On dÃĐfinit les ÃĐtats que l'on veut prendre en compte :
UIManager.put("TextField.States", "Enabled,Disabled,MouseOver,Focused,Selected,Pressed,Empty");
// 2. On associe notre ÃĐtat à la clef du mÊme nom :
UIManager.put("TextField.Empty", new State<JTextField>("Empty") {
@Override
protected boolean isInState(JTextField c) {
Document doc = c.getDocument();
// On considÃĻre le JTextField vide lorsqu'il
// n'y a pas de Document ou qu'il est vide :
return doc==null || doc.getLength()==0;
}
});Attention à bien redÃĐfinir les ÃĐtats standards dans la propriÃĐtÃĐ Composant.States. Sinon il ne seront plus pris en compte. De mÊme la mÃĐthode isInState() risque d'Être exÃĐcutÃĐe un grand nombre de fois, il faut donc ÃĐviter d'y faire des traitements trop complexes...
On notera que certains composants comportent dÃĐjà des ÃĐtats personnalisÃĐs. Par exemple les JComboBox peuvent Être Editable, les JProgressBar peuvent Être Indeterminate ou Finished...
Les Painters▲
Nimbus dessine tous les composants graphiques à partir de Painters, via l'interface javax.swing.Painter qui dÃĐfinit une seule et unique mÃĐthode, de la maniÃĻre suivante :
public interface Painter<T> {
public void paint(Graphics2D g, T object, int width, int height);
}L'unique objectif de cette interface consiste à dessiner un objet (un composant ou une partie du composant). Nimbus l'utilise de maniÃĻre assez intense pour chaque ÃĐtat ou partie des composants. Chaque Painter ÃĐtant dÃĐfini via une propriÃĐtÃĐ de l'UIManager, il est alors possible de modifier le rendu d'un composant via Java 2D.
UIManager.put("Button[Enabled].backgroundPainter", new Painter<JButton>() {
@Override
public void paint(Graphics2D g, JButton button, int width, int height) {
g.setColor(button.getBackground());
g.fill3DRect(0, 0, width, height, true);
}
});
// Note : il faut bien entendu faire la mÊme chose pour tous les ÃĐtats pour avoir un rÃĐsultat final cohÃĐrent.Cette technique peut permettre de configurer grandement le rendu du composant. Mais elle possÃĻde plusieurs limitations. D'une part elle requiert une bonne maitrise de Java 2D afin d'obtenir un rÃĐsultat agrÃĐable à l??il, mais cela oblige ÃĐgalement à implÃĐmenter plusieurs painters selon l'ÃĐtat du composant. Enfin, il est malheureusement impossible de rÃĐutiliser les painters de Nimbus, puisque ces derniers ne sont pas publics...
Tailles des composants▲
Nimbus gÃĻre ÃĐgalement quatre tailles de composant via les propriÃĐtÃĐs client des composants Swing. En plus de la taille "standard" par dÃĐfaut, on dispose donc des tailles "mini", "small" et "large", que l'on applique via putClientProperty() avec la clef JComponent.sizeVariant :
component.putClientProperty("JComponent.sizeVariant", "small");à noter toutefois que le composant doit Être mis à jour via updateUI() afin que le changement soit bien pris en compte (cela permet de rÃĐinitialiser les caractÃĐristiques du composant).
On peut ÃĐgalement utiliser SwingUtilities.updateComponentTreeUI() pour mettre à jour tous les sous-composants d'un composant ou d'une fenÊtre.
UIManager.setLookAndFeel("javax.swing.plaf.nimbus.NimbusLookAndFeel");
JPanel panel = new JPanel();
for (String size : "mini,small,normal,large".split(",")) {
JButton button = new JButton(size);
button.putClientProperty("JComponent.sizeVariant", size);
panel.add(button);
}
SwingUtilities.updateComponentTreeUI(panel);
JOptionPane.showMessageDialog(null, panel);
PropriÃĐtÃĐs propres à un composant▲
Enfin, Nimbus nous offre la possibilitÃĐ de redÃĐfinir des propriÃĐtÃĐs de l'UIManager pour chaque composant en lui associant un objet UIDefault contenant les propriÃĐtÃĐs qui lui sont propres :
JButton button = ...
UIDefaults overrides = new UIDefaults();
overrides.put("Button[Enabled].backgroundPainter", new Painter<JButton>() {
@Override
public void paint(Graphics2D g, JButton button, int width, int height) {
g.setColor(button.getBackground());
g.fill3DRect(0, 0, width, height, true);
}
});
button.putClientProperty("Nimbus.Overrides", overrides);Ã noter ÃĐgalement la propriÃĐtÃĐ cliente Nimbus.Overrides.InheritDefaults qui permet d'indiquer si l'on souhaite hÃĐriter des propriÃĐtÃĐs de base de l'UIManager.
UIDefaults overrides = ...
button.putClientProperty("Nimbus.Overrides", overrides);
button.putClientProperty("Nimbus.Overrides.InheritDefaults", false);AmÃĐliorations de la machine virtuelle▲
Contrairement à l'API Java qui reste gÃĐnÃĐralement "figÃĐe" entre deux versions, la machine virtuelle est en perpÃĐtuelle ÃĐvolution. Son compilateur HotSpot est constamment amÃĐliorÃĐ et optimisÃĐ afin d'offrir les meilleures performances.
Les nouveautÃĐs prÃĐsentÃĐes ne le sont pas forcÃĐment dans le sens oÃđ elles ont dÃĐjà ÃĐtÃĐ introduites dans les diffÃĐrentes updates de Java 6 (ou rÃĐtroportÃĐes). Elles correspondent gÃĐnÃĐralement à des options expÃĐrimentales qui sont dÃĐsormais activÃĐes par dÃĐfaut.
Tiered Compilation▲
La JVM de Sun/Oracle dispose de deux compilateurs JIT : "client" et "server".
Si le compilateur "client" se rÃĐvÃĻle trÃĻs rapide au dÃĐmarrage, le compilateur "server" propose quant à lui de bien meilleures performances grÃĒce à un profilage et une recompilation native du code bien plus poussÃĐs...
Le concept de "tiered compilation" (que l'on pourrait traduire par "compilation à plusieurs niveaux") consiste à cumuler le meilleur des deux mondes, c'est-à -dire de bÃĐnÃĐficier d'un temps de dÃĐmarrage rapide tout en permettant le meilleur profilage du code, et donc les meilleures optimisations possible. Pour cela, il s'applique à lui-mÊme les mÊmes rÃĻgles de profilage et d'optimisation...
Pour activer cela, il faut lancer la JVM avec les options -server -XX:+TieredCompilation afin d'activer le mode "server" et la compilation à plusieurs niveaux.
java -server -XX:+TieredCompilation ...Compressed Oops▲
Dans le dialecte de la JVM, un Oop (Ordinary object pointer) correspond tout simplement à un pointeur vers un objet Java, dont la taille correspond à la taille des pointeurs sur la machine hÃīte. Ainsi, sur une architecture 32 bits un pointeur occupera 32 bits, tandis qu'il en occupera le double sur une architecture 64 bits.
Les architectures 64 bits ont plusieurs avantages, dont celui permettant de dÃĐpasser allÃĻgrement la limite des 4 Go de mÃĐmoire maximum pour le heap (paramÃĻtre -Xmx). En fait il n'y a plus vraiment de limite. Mais en contrepartie cela implique ÃĐgalement en moyenne une utilisation mÃĐmoire plus importante pour un mÊme programme du fait que toutes les rÃĐfÃĐrences occuperont un espace mÃĐmoire plus grand...
La notion de "Compressed Oops" consiste donc tout logiquement à compresser la majeure partie des pointeurs 64 bits afin qu'ils n'occupent pas plus de place qu'un pointeur 32 bits. La valeur des pointeurs est ÃĐvaluÃĐe selon sa valeur "compressÃĐe" et l'adresse mÃĐmoire du dÃĐbut de l'espace mÃĐmoire heap. Cela permettra donc à la majoritÃĐ des programmes de fonctionner en mode 64 bits sans avoir forcÃĐment besoin de beaucoup plus de mÃĐmoire qu'en mode 32 bits. En contrepartie cela implique quand mÊme une nouvelle limite pour le heap de 32 Go (ce qui est malgrÃĐ tout 8 fois plus important que la limite des 4 Go du 32 bits).
Avec Java 7, les "compressed oops" sont activÃĐs par dÃĐfaut sur toutes les JVM 64 bits dont la taille max du heap est infÃĐrieure à 32 Go. Ils sont automatiquement dÃĐsactivÃĐs au-delà de cette limite puisqu'il est impÃĐratif d'utiliser des pointeurs 64 bits pour reprÃĐsenter un tel espace de stockage.
Cette option est ÃĐgalement activÃĐe par dÃĐfaut depuis l'update 23 de Java 6, et il est possible de la forcer sur les versions prÃĐcÃĐdentes de Java 6 via l'option -XX:+UseCompressedOops.
Zero-Based Compressed Oops▲
Lorsqu'on utilise les "Compressed Oops" dans une JVM 64 bits, cette derniÃĻre demande au systÃĻme d'exploitation hÃīte de lui fournir un espace mÃĐmoire qui commence à une adresse virtuelle de "zÃĐro" pour le heap.
Cela permet de simplifier l'encodage/dÃĐcodage des pointeurs 64 bits en 32 bits puisqu'il n'y plus à gÃĐrer l'adresse de base du heap, ce qui est bien plus efficace pour les heaps infÃĐrieurs à 4 Go (ce qui doit quand mÊme correspondre à une grosse majoritÃĐ des applications).
L'allocation du heap avec une adresse virtuelle "zÃĐro" est gÃĐnÃĐralement possible jusqu'Ã 26 Go sur les principaux systÃĻmes d'exploitation (Windows, Linux et Solaris).
Escape Analysis▲
Lors de l'analyse du code d'une mÃĐthode, le compilateur JIT dÃĐterminera pour chaque objet crÃĐÃĐ localement un statut d'ÃĐchappement, qui peut prendre trois valeurs possibles :
- GlobalEscape lorsque l'objet est partagÃĐ en dehors de la mÃĐthode ou du thread. Par exemple s'il est stockÃĐ dans un attribut static, dans un attribut d'instance d'un autre objet, ou tout simplement s'il est utilisÃĐ comme valeur de retour de la mÃĐthode ;
- ArgEscape lorsque l'objet provient d'un paramÃĻtre de la mÃĐthode ou qu'il est passÃĐ Ã un paramÃĻtre d'une autre mÃĐthode, à condition qu'il n'entre jamais dans la premiÃĻre catÃĐgorie. Bref que l'objet soit partagÃĐ en dehors de la mÃĐthode tout en restant inaccessible depuis un autre thread ;
- enfin, NoEscape pour les objets utilisÃĐs uniquement dans le corps de la mÃĐthode.
à partir de ces informations, le compilateur JIT peut donc effectuer un certain nombre d'optimisations plus poussÃĐes, selon le cas.
Les ÃĐlÃĐments non-GlobalEscape restent limitÃĐs au thread courant, ce qui rend toute synchronisation inutile. Le compilateur peut ainsi "supprimer" les ÃĐventuels locks associÃĐs à ces variables (que ce soit directement ou via l'appel d'une mÃĐthode synchronized). L'utilisation d'objet synchrone comme Vector ou StringBuffer s'effectuera donc sans synchronisation dans ce cas-là .
Mais il y a plus intÃĐressant : le compilateur peut ÃĐgalement directement remplacer des objets locaux par leurs valeurs, en supprimant toute allocation inutile. Cela permet en particulier de passer outre toutes les copies d'objets par protection. Prenons l'exemple suivant permettant de calculer l'aire d'un composant graphique :
public static int getArea(Component component) {
Dimension dim = component.getSize();
return dim.width * dim.height;
}La mÃĐthode getSize() se contentant de retourner new Dimension(width, height), le compilateur peut dÃĐjà optimiser cela via de l'inlining de mÃĐthode en supprimant l'appel de mÃĐthode, comme ceci :
public static int getArea(Component component) {
Dimension dim = new Dimension(component.width, component.height);
return dim.width * dim.height;
}C'est là que l'Escape Analysis rentre en jeu. Puisque la variable "dim" reste locale à la mÃĐthode, son utilisation peut Être dÃĐtaillÃĐe et donc optimisÃĐe. Ici l'objet Dimension est crÃĐÃĐ uniquement pour accÃĐder à ses valeurs width et height sans les modifier. L'allocation de l'objet est complÃĻtement inutile et peut donc Être ignorÃĐe. Pour cela le compilateur JIT va remplacer les ÃĐventuelles mÃĐthodes par de l'inlining, et ses attributs d'instance par des variables locales (qui pourront donc Être stockÃĐes dans le registre).
public static int getArea(Component component) {
int width = component.width;
int height = component.height;
return dim.width * dim.height;
}L'allocation inutile a donc ÃĐtÃĐ supprimÃĐe au profit de l'accÃĻs direct aux attributs en les remplaçant par des variables locales, malgrÃĐ que ceux-ci ne soient pas directement visibles...
à titre d'information, sur ma machine il faut environ 900 millisecondes pour exÃĐcuter cette mÃĐthode 100 millions de fois. Avec l'Escape Analysis on tombe à 40 millisecondes...
L'Escape Analysis est activÃĐ par dÃĐfaut depuis Java 6 update 23. Il reste toutefois possible de la dÃĐsactiver avec l'option -XX:-DoEscapeAnalysis.
NUMA Collector Enhancements▲
Le garbage collector "Parallel" (ParallelGC) a ÃĐtÃĐ amÃĐliorÃĐ afin de prendre en compte les architectures NUMA (Non Uniform Memory Access), qui offrent un temps d'accÃĻs diffÃĐrent à la mÃĐmoire selon son emplacement. En fait chaque processeur dispose d'une mÃĐmoire locale plus rapide, qui est couplÃĐe à une mÃĐmoire distante plus lente mais plus importante.
Le ParallelGC positionne donc les objets dans diffÃĐrents emplacements mÃĐmoire selon le thread qui les a instanciÃĐs et selon leurs utilisations, afin d'offrir de meilleures performances globales.
à noter que le support des architectures NUMA n'est disponible que sur les systÃĻmes Solaris 9 12/02 ou Linux kernel 2.6.19 (glibc 2.6.1) ou supÃĐrieurs. Pour l'activer il faut utiliser le flag -XX:+UseNUMA couplÃĐs au flag -XX:+UseParallelGC (pour activer le ParallelGC).
D'aprÃĻs Oracle, le support des architectures NUMA apporterait un gain de performance de 30 % sur le benchmark SPEC JBB 2005 avec une machine Opteron 32 bits à 8 processeurs. En 64 bits le gain de performance atteindrait les 40 %...
Les tout petits plus...▲
Comme chaque nouvelle version, Java 7 apporte ÃĐgalement son lot de modifications mineures, mais pas forcÃĐment dÃĐnuÃĐes d'intÃĐrÊt pour autant.
En voici une petite liste non exhaustive agrÃĐmentÃĐe d'exemples, c'est toujours plus parlant !
La JSR 203 en profite ÃĐgalement pour amÃĐliorer le support des sockets dans l'API standard. On notera par exemple l'ajout de plusieurs interfaces intermÃĐdiaires (NetworkChannel, MulticastChannel, etc.) et une API d'option de socket plus ÃĐvolutive que les simples constantes numÃĐriques utilisÃĐes jusqu'Ã maintenant.
SocketAddress remote = ...
SocketChannel channel = SocketChannel.open(remote)
.setOption(StandardSocketOptions.SO_KEEPALIVE, true)
.setOption(StandardSocketOptions.SO_SNDBUF, 8192),La classe Random ne doit pas Être partagÃĐe par plusieurs threads, car cela peut engendrer une mauvaise qualitÃĐ des nombres alÃĐatoires. La classe ThreadLocalRandom vient pallier cela en proposant une implÃĐmentation spÃĐcifique à chaque thread que l'on rÃĐcupÃĻre via la mÃĐthode ThreadLocalRandom.current()
int value = ThreadLocalRandom.current().nextInt();L'autoboxing du compilateur accepte dÃĐsormais les casts d'un Object directement vers un type primitif, sans avoir à utiliser le type wrapper correspondant.
Object object = ...
// Java 6 et Java 5 :
int value = (Integer) object;
// Java 7 :
int value = (int) object;Afin de faciliter l'ÃĐcriture de Comparateur, les classes Boolean, Byte, Character, Short, Integer et Long se voient dotÃĐes d'une mÃĐthode static compare(x,y) permettant de comparer deux valeurs primitives de la mÊme maniÃĻre que la mÃĐthode d'instance compareTo(). Les types Float et Double ne sont pas concernÃĐs puisqu'ils disposaient dÃĐjà d'une telle mÃĐthode. Bien sÃŧr ces implÃĐmentations sont relativement basiques, mais leur mise à disposition permet d'ÃĐviter les petites erreurs en proposant une implÃĐmentation de base pour tous les types primitifs.
int diff = Boolean.compare(true, false);
int diff = Byte.compare((byte)0, (byte)1);
int diff = Character.compare('a', 'b');
int diff = Short.compare((short)0, (short)1);
int diff = Integer.compare(0, 1);
int diff = Long.compare(0L, 1L);
int diff = Float.compare(0.0f, 1.0f);
int diff = Double.compare(0.0, 1.0);De mÊme, les mÃĐthodes parseXXX() des types Byte, Short, Integer et Long acceptent dÃĐsormais le caractÃĻre '+' devant les nombres positifs (jusqu'à prÃĐsent cela gÃĐnÃĐrait une exception). Ceci permet de s'aligner sur le comportement de leurs ÃĐquivalents pour les nombres rÃĐels parseFloat() et parseDouble().
int value = Integer.parseInt("+1"); // OKReflectiveOperationException est une nouvelle exception parente aux exceptions gÃĐnÃĐrÃĐes via l'API de Reflection (ClassNotFoundException, IllegalAccessException, InstantiationException, InvocationTargetException, NoSuchFieldException, NoSuchMethodException), ce qui permet d'intercepter toutes ces exceptions dans un seul bloc catch facilement.
// Java 6 et antÃĐrieures :
try {
String methodName = "toUpperCase";
Object instance = "a String";
Method method = instance.getClass().getDeclaredMethod(methodName);
method.invoke(instance);
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (IllegalArgumentException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
} catch (NoSuchMethodException e) {
e.printStackTrace();
}
// Java 7 :
try {
String methodName = "toUpperCase";
Object instance = "a String";
Method method = instance.getClass().getDeclaredMethod(methodName);
method.invoke(instance);
} catch (ReflectiveOperationException e) {
e.printStackTrace();
}System.lineSeparator() remplacera avantageusement System.getProperty(line.separator).
// Java 6 et antÃĐrieures :
String endl = System.getProperty("line.separator");
// Java 7 :
String endl = System.lineSeparator();Les flux d'entrÃĐes/sorties des processus externes ont ÃĐtÃĐ amÃĐliorÃĐs. La classe ProcessBuilder permet dÃĐsormais de les rediriger automatiquement vers un fichier, ou d'hÃĐriter directement des mÊmes flux d'entrÃĐes/sorties que le processus Java (les flux seront alors directement associÃĐs aux flux correspondants du process Java, sans que l'on ait besoin de gÃĐrer quoi que ce soit).
// ExÃĐcution d'un processus externe en hÃĐritant des flux d'entrÃĐes/sorties
// (il n'y a donc pas besoin de traiter les flux du process)
Process process = new ProcessBuilder("programme", "arg1", "arg2")
.inheritIO().start();
// ExÃĐcution d'un processus externe en hÃĐritant des flux d'entrÃĐes/sorties
// ET en redirigeant la sortie standard dans un fichier :
Process process = new ProcessBuilder(ls)
.inheritIO().redirectOutput(new File("out.txt")).start();java.util.Objects propose un ensemble de mÃĐthode static facilitant certains traitements sur les objets, comme par exemple des mÃĐthodes compare(), equals(), hashCode() ou toString() gÃĐrant automatiquement les valeurs nulles, hash() qui permet de calculer facilement un hashcode, ou encore requireNonNull() qui vÃĐrifiera la validitÃĐ d'une rÃĐfÃĐrence.
class MyObject {
private final String name;
private final Date date;
private final Date expir;
public MyObject(String name, Date date, Date expir) {
// VÃĐrification automatique des valeurs nulles
// Ceci gÃĐnÃĐrera une NullPointerException
// si le paramÃĻtre est null.
this.name = Objects.requireNonNull(name);
// On peut dÃĐfinir un message perso en cas d'exception :
this.date = Objects.requireNonNull(date, date is null);
// Ce paramÃĻtre peut Être null :
this.expir = expir;
}
@Override
public int hashCode() {
// Calcul du hashCode selon ces attributs, en gÃĐrant les null ÃĐventuels :
return Objects.hash(this.name, this.date, this.expir);
}
@Override
public boolean equals(Object obj) {
if (this==obj)
return true;
if (obj instanceof MyObject) {
MyObject other = (MyObject)obj;
// VÃĐrification de l'ÃĐgalitÃĐ des attributs
// (en gÃĐrant proprement les valeurs nulles) :
return Objects.equals(this.name, other.name)
&& Objects.equals(this.date, other.date)
&& Objects.equals(this.expir, other.expir);
}
return false;
}
@Override
public String toString() {
// Objects.toString() nous permet de dÃĐfinir une valeur
// dans le cas oÃđ la valeur de this.expir serait nulle
return this.name + " " + this.date + " " +
Objects.toString(this.expir, "(absent)");
}
}Le compilateur javac accepte dÃĐsormais l'option -Werror, qui permet de considÃĐrer tous les warnings comme des erreurs et donc d'interrompre la compilation. Ã utiliser conjointement avec -Xlint pour activer tous les warnings, et donc s'assurer d'un code plus robuste.
Date date = new Date(111, 1, 1); > javac Code.java
Note: Code.java uses or overrides a deprecated API.
Note: Recompile with -Xlint:deprecation for details. > javac -Xlint Code.java
Main.java:7: warning: [deprecation] Date(int,int,int) in Date has been deprecated
Date date = new Date(111, 1, 1);
^
1 warning > javac -Xlint -Werror Code.java
Main.java:7: warning: [deprecation] Date(int,int,int) in Date has been deprecated
Date date = new Date(111, 1, 1);
^
error: warnings found and -Werror specified
1 error
1 warningSwing utilise dÃĐsormais les Generics. Outre les nouveaux ÃĐlÃĐments comme Painter<T> ou JLayer<V extends Component>, on peut noter l'ÃĐvolution des classes JList et JComboBox respectivement en JList<E> et JComboBox<E>...
JList<Date> listDate = new JList<Date>();
JComboBox<String> combo = new JComboBox<String>();La classe URLClassLoader dispose dÃĐsormais d'une mÃĐthode close(), permettant de libÃĐrer les ressources liÃĐes pour ÃĐventuellement les modifier ou les recharger...
La classe StandardCharsets dÃĐfinit des attributs static permettant un accÃĻs direct aux codages de caractÃĻres les plus courants, qui sont forcÃĐment prÃĐsents dans toutes les plateformes Java, soit : US_ASCII, ISO_8859_1, UTF8, UTF_16, UTF16_LE et UTF16_BE.
Path path = ...
List<String> lines = Files.readAllLines(path, StandardCharsets.UTF_8);La classe Locale supporte dÃĐsormais la notation internationale IETF BCP 47, qui apporte la notion de script et d'extension. La crÃĐation de Locale peut donc dÃĐsormais s'effectuer via la mÃĐthode static Locale.forLanguageTag() ou via la classe Locale.Builder().
Dans le mÊme ordre, il est dÃĐsormais possible de dÃĐfinir deux catÃĐgories de locales par dÃĐfaut via l'enum Locale.Category, afin de distinguer la langue de l'interface utilisateur de celle utilisÃĐe pour le formatage des donnÃĐes.
// CrÃĐation d'une locale complexe à partir d'un tag IETF BCP 47
Locale japanese = Locale.forLanguageTag("ja-JP-u-ca-japanese-x-lvariant-JP");
// Utilisation de deux locales par dÃĐfaut :
// L'interface utilisateur sera en français :
Locale.setDefault(Category.DISPLAY, Locale.FRENCH);
// Tandis que le formatage des nombres/dates sera en anglais US :
Locale.setDefault(Category.FORMAT, Locale.US);Java 7 inclut ÃĐgalement le support de l'Unicode version 6.0. Pour le dÃĐveloppeur, c'est totalement transparent, mises à part quelques nouvelles mÃĐthodes utilitaires au sein de la classe Character...
Vers Java 8 et au-delà ...▲
J'ai essayÃĐ de faire une prÃĐsentation globale des nouveautÃĐs apportÃĐes par Java SE 7, plus ou moins complÃĻte selon les sections. Bien entendu pour approfondir tout cela il reste la javadoc, qui est source d'exemples et de dÃĐtails intÃĐressants dont il serait bÊte de se priver.
Enfin il ne faut pas oublier non plus que Java SE 7 est intimement liÃĐ Ã son successeur Java SE 8. En effet le fameux "Plan B" y a reportÃĐ plusieurs des fonctionnalitÃĐs initialement prÃĐvues pour Java 7.
On pense au projet Jigsaw, un systÃĻme de modularisation de la plateforme Java, Ã l'usage ÃĐtendu des annotations, au support d'expressions littÃĐrales pour les collections (List, Set et Map), et surtout aux expressions Lambdas et leurs lots de nouveaux concepts (type "SAM", rÃĐfÃĐrence de mÃĐthode, defender's methods, etc.) qui permettront un nouveau genre d'API tout en amÃĐliorant grandement l'utilisation des API actuelles.
Mais c'est une autre histoire...